At most of the places I’ve worked, the primary language used was not what I gravitated to naturally. If you’re going to ask for a language of choice personally, it’s python. I appreciate the explicit nature, that it’s often pseudocode that can execute and it has a rich ecosystem of libraries (though that’s most languages these days). But as much as anything I latched onto Django in its early days. If you’re not familiar with Django it’s a popular framework for web apps written in Python. What I loved about it in particular was one of its taglines early on: batteries included.
For Django batteries included meant it had:
Built-in ORM
Authentication
Admin tooling
Template engine
Middleware layer
and more
Just recently I was on the changelog Podcast talking about “What’s so exciting about Postgres?” I talked for a while and probably could have kept going, a lot of these features are top of mind in what we’re building with Crunchy Bridge. In reflecting on things a bit I can see a big parallel personally to what I appreciated in Django in Postgres. To me Postgres is the batteries included database. So what’s in the PostgreSQL box:
Solid database foundations
Expressive SQL
Full text search
Geospatial support
Extensions
Solid Database Foundations
To me, there are few things more important than data. And knowing my data is safe and secure is really key. Whether it’s my bank balance or my food order, when I transact in some way I want to know the data is there. Same applies for the applications I build and PostgreSQL has had a long sturdy track record here of being a safe and reliable database. At its core Postgres MVCC is a reliable way to help ensure a level of transactional consistency while still operating at large scale. Hundreds of thousands of transactions per second really can be quite manageable in a single PostgreSQL instance.
It has also evolved over the years to be as powerful as it is reliable. Data types are a big piece of that. Data types may on the cover not seem like something to write home about, yet not all databases have support for types that you’re using on a daily basis in your application. Just a few noteworthy ones:
range types – especially useful for calendaring when you need from and to, which come with an ability to enforce constraints.
timestamps – working with time in any language is painful, timestamps with timezone make conversion easier, coupled with time intervals getting things like users that signed up in last hour is trivial.
JSONB – this one has gotten plenty of attention over the years, but it’s still new to many. A binary JSON datatype that you can easily index with GIN indexes.
Expressive SQL
SQL is the lingua franca for data. SQL’s origins in relational algebra and relational calculus make it a well thought out language for working with data – even if it isn’t always the most beautiful language to read. SQL is the standard language for data that every NoSQL database that doesn’t have it eventually recreates their version of SQL because it’s simply the right answer for data.
Within Postgres you’ve got all the standard ways of accessing data, and then you’ve also got the more exotic:
CTEs (Common Table Expressions) – useful for composing more complex queries, recursion, and making SQL readable.
Window functions – great for analytics such as ordering results, calculating things like median and percentiles.
Functions – Postgres comes with a ton of functions already to make common actions like date math, parsing out characters and other things trivial.
The broader sentiment here, is that if you have an existing application and you’re adding search to it, before you go and reach for elastic (which you then have to sync data to, and maintain and support that system) consider using something that you already have supported and contains the data – Postgres.
Geospatial support
This is a whole bucket in and of itself. PostGIS is the most advanced geospatial open source database. It’s an extension to Postgres but I put it in a special class from other extensions. While extensions are becoming more and more advanced, PostGIS has been pretty rich and advanced from day one. PostGIS has its own community that runs a bit parallel to Postgres, releasing new major and minor versions of the extension at a regular cadence.
When you enable PostGIS (simply CREATE EXTENSION postgis;) you instantly have a geospatial database. It brings new data types, new spatial predicates for querying and interacting with those geometries. You can go further and enable pgRouting which helps for route planning. Looking to figure out how to optimize 10 food deliveries across 3 drivers for optimum route and timing? PostGIS can help.
In fact we just wrapped up a marathon PostGIS day that started early on the east coast, and wrapped up late on the west coast. While the day has since wrapped up, we’ll be posting those talks in the near future so feel free to sign up if you want to get some updates when those are live.
Extensions
I guess I went a bit out of order here leading with PostGIS. Backing up a bit… extensions are unique to Postgres. Personally the name doesn’t really do much to convey the power and value of them. Extensions allow you to expand and change what Postgres can do, but what’s unique is what Postgres allows. Postgres has these deep low level hooks that allow you to do things like add new data types, new functions, even hooks into the query planner.
Postgres comes with some stock extensions, you may still have to enable them, but they’re at least available to you. pg_stat_statements is one of the most useful extensions that exists, it was written and updated in Postgres 9.2 by my colleague Peter Geoghegan to be incredibly useful. It will give you an almost immediate 30,000 foot view on database performance without having to go deep diving into your application to understand which queries are being called.
The list of extensions is pretty long. PGXN, the Postgres Extension Network, has an index of over 200 extensions, some more production ready than others. All could be worthy of their own deep dive but a few particular ones worthy of some highlight:
pg_partman – An extension that builds on native time partitioning in Postgres to make working with time series data simple and performant. A nice bonus for me, this one is maintained by a Crunchy Data colleague.
pgsql-http – A simple extension, but potentially incredibly useful one that allows you to make http requests. Want to trigger a web hook? Call out to an API from your plpsql or plpython?
zhparser, pgroonga – I group these two together despite being two different extensions. If you’re looking for full text search but the native Postgres support doesn’t work (the case for Japanese and Chinese). Here is your answer.
madlib – Who needs an entire ETL and data science pipeline when you can do it all where the data lives (in Postgres). Madlib isn’t a new hobby library from some weekend dabbling, it’s nearly 10 years old and has rich support for data science broadly. Naive bayes, k-means, sketch estimations – those have all been in there since it’s 1.0 release in 2011. It’s part of the Apache foundation, and continues to evolve and simply make data science in your Postgres accessible.
postgres_fdw – Foreign Data Wrappers (FDWs) are an interesting class of extension that allow you to query from within Postgres to something else (read: another Postgres, Redis, Mongo, you name it). If any of the FDWs are production ready it’s the Postgres one which ships with Postgres itself.
A big part of the goal of Crunchy Bridge, our multi-cloud PostgreSQL managed service, is to take advantage of the broad ecosystem of extensions so you can do more with your database.
The question isn’t why Postgres, it’s why not Postgres?
Over 8 years ago I wrote a blog post explaining “Why Postgres” was a database you should consider using. Five years later I posted a new version with some updates. I haven’t even gotten to the fascinating future that could exist with extensions or pluggable storage. (Want columnar storage in Postgres… I promise it’ll be here one day, maybe sooner than you think).
But today you don’t need a reason for choosing Postgres, if you do all your answers are above. Today the question has really shifted to what are you not using Postgres for, and how can the community better support that happening natively in Postgres in the future.
This is core to what we do Crunchy Data and what we believe. As a community how can we advance Postgres as a great open source database and continue to include more within it? It’s the reason we’ve spent nearly 10 years now ourselves helping folks run and support production PostgreSQL, whether VM based HA setups, on Kubernetes with our PostgreSQL Operator, or most recently on our database as a service.
As I look at the Django website today I see “batteries included” has mostly faded from the primary pitch for the framework, so I’m taking this opportunity to commandeer the phrase for Postgres, it really is a full batteries included database.
Traditionally, MySQL has been used to power most of the backend services at Bolt. We’ve designed our schemas in a way that they’re sharded into different MySQL clusters. Each MySQL cluster contains a subset of data and consists of one primary and multiple replication nodes.
Once data is persisted to the database, we use the Debezium MySQL Connector to capture data change events and send them to Kafka. This gives us an easy and reliable way to communicate changes between back-end microservices.
Vitess at Bolt
Bolt has grown considerably over the past few years, and so did the volume of data written to MySQL. Manual database sharding has become quite an expensive and long-lasting process prone to errors. So we started to evaluate more scalable databases, one of which is Vitess. Vitess is an open-source database clustering system that is based on MySQL and provides horizontal scalability for it. Originated and battle-tested at YouTube, it was later open-sourced and is used by companies like Slack, Github, JD.com to power their backend storage. It combines important MySQL features with the scalability of a NoSQL database.
One of the most important features that Vitess provides is its built-in sharding. It allows the database to grow horizontally by adding new shards in a way that is transparent to back-end application logic. To your application, Vitess appears like a giant single database, but in fact data is partitioned into multiple physical shards behind the scenes. For any table, an arbitrary column can be chosen as the sharding key, and all inserts and updates will be seamlessly directed to a proper shard by Vitess itself.
Figure 1 below illustrates how back-end services interact with Vitess. At a high level, services connect to stateless VTGate instances through a load balancer. Each VTGate has the Vitess cluster’s topology cached in its memory and redirects queries to the correct shards and the correct VTTablet (and its underlying MySQL instance) within the shards. More on VTTablet is written below.
Failover (a.k.a. Reparenting) is easy and transparent for clients. Clients only talk to a VTGate who takes care of failover and service discovery of the new primary transparently.
It automatically rewrites “problematic” queries that could potentially cause database performance degradation.
It has a caching mechanism that prevents duplicate queries to reach the underlying MySQL database simultaneously. Only one query will reach the database and its result will be cached and returned to answer duplicate queries.
It has its connection pool and eliminates the high-memory overhead of MySQL connections. As a result, it can easily handle thousands of connections at the same time.
Connection timeout and transaction timeout can be configured.
It has minimal downtime when doing resharding operations.
Its VStream feature can be used by downstream CDC applications to read change events from Vitess.
Streaming Vitess Options
The ability to capture data changes and publish them to Apache Kafka was one of the requirements for adopting Vitess at Bolt. There were several different options we’ve considered.
Option 1: Using Debezium MySQL Connector
Applications connect to Vitess VTGate to send queries. VTGate supports the MySQL protocol and has a SQL parser. You can use any MySQL client (e.g. JDBC) to connect to VTGate, which redirects your query to the correct shard and returns the result to your client.
However, VTGate is not equal to a MySQL instance, it is rather a stateless proxy to various MySQL instances. For the MySQL connector to receive change events, the Debezium MySQL connector needs to connect to a real MySQL instance. To make it more obvious, VTGate also has some known compatibility issues, which makes connecting to VTGate different from MySQL.
Another option is to use the Debezium MySQL Connector to connect directly to the underlying MySQL instances of different shards. It has its advantages and disadvantages.
One advantage is that for an unsharded keyspace (Vitess’s terminology for a database), the MySQL Connector can continue to work correctly and we don’t need to include additional logic or specific implementation. It should just work fine.
One of the biggest disadvantages is that resharding operations would become more complex. For example, the GTID of the original MySQL instance would change when resharded, and the MySQL connector depends on the GTID to work correctly. We also believe that having the MySQL connector connected directly to each underlying MySQL instance defies the purpose of Vitess’s operational simplicity as a new connector has to be added (or removed) each time resharding is done. Not to mention that such an operation would lead to data duplication inside Kafka brokers.
Option 2: Using JDBC Source Connector
We’ve also considered using the JDBC Source Connector. It allows sourcing data from any relational databases that support the JDBC driver into Kafka. Therefore, it is compatible with Vitess VTGate. It has its advantages and disadvantages as well.
Advantages:
It is compatible with VTGate.
It handles Vitess resharding operation better. During resharding operation, reads are simply automatically redirected (by VTGate) to the target shards. It won’t generate any duplicates or lose any data.
Disadvantages:
It is poll-based, meaning that the connector polls the database for new change events on a defined interval (typically every few seconds). This means that we would have a much higher latency, compared to the Debezium MySQL Connector.
Its offsets are managed by either the table’s incremental primary key or one of the table’s timestamp columns. If we use the timestamp column for offset, we’d have to create a secondary-index of the timestamp column for each table. This adds more constraints on our backend services. If we use the incremental primary key, we would miss the change events for row-updates because the primary key is simply not updated.
The topic name created by the JDBC connector doesn’t include the table’s schema name. Using the topic.prefix connector configuration would mean that we’ll have one connector per schema. At Bolt, we have a large number of schemas, which means we would need to create a large number of JDBC Source Connectors.
At Bolt, our downstream applications are already set up to use Debezium’s data formats and topic naming conventions, we’d need to change our downstream application’s decoding logic to the new data formats.
Row deletes are not captured.
Option 3: Using VStream gRPC
VTGate exposes a gRPC service called VStream. It is a server-side streaming service. Any gRPC client can subscribe to the VStream service to get a continuous stream of change events from the underlying MySQL instances. The change events that VStream emits have similar information to the MySQL binary logs of the underlying MySQL instances. A single VStream can even subscribe to multiple shards for a given keyspace, making it quite a convenient API to build CDC tools.
Behind the scene, as shown in Figure 2, VStream reads change events from multiple VTTablets – one VTTablet per shard. Therefore, it doesn’t send duplicates from multiple VTTablets for a given shard. Each VTTablet is a proxy to its MySQL instance. A typical topology would include one master VTTablet and its corresponding MySQL instance, and multiple replica VTTablets, each of which is the proxy of its own replica MySQL instance. A VTTablet gets change events from its underlying MySQL instance and sends the change events back to VTGate, which in turn sends the change events back to VStream’s gRPC client.
When subscribing to the VStream service, the client can specify a VGTID and Tablet Type (e.g. MASTER, REPLICA). The VGTID tells the position from which VStream starts to send change events. Essentially, VGTID includes a list of (keyspace, shard, shard GTID) tuples. The Tablet Type tells which MySQL instance (primary or replica) in each shard do we read change events from.
It is a simple way to receive change events from Vitess. It is also recommended in Vitess’s documentation to use VStream to build CDC processes downstream.
VTGate hides the complexity of connecting to various source MySQL instances.
It has low latency since change events are streamed to the client as soon as they happen.
The change events include not only inserts and updates, but also deletes.
Probably one of the biggest advantages is that the change events contain the schema of each table. So you don’t have to worry about fetching each table’s schema in advance (by, for example, parsing DDLs or querying the table’s definition).
The change events have VGTID included, which the CDC process can store and use as the offset from where to restart the CDC process next time.
Also importantly, VStream is designed to work well with Vitess operations such as Resharding and Moving Tables.
There are also some disadvantages:
Although it includes table schemas, some important information is still missing. For example, the Enum and Set column types don’t provide all the allowed values yet. This should be fixed in the next major release (Vitess 9) though.
Since VStream is a gRPC service, we cannot use the Debezium MySQL Connector out-of-the-box. However, it is quite straightforward to implement the gRPC client in other languages.
All things considered, we’ve decided to use VStream gRPC to capture change events from Vitess and implement our Vitess Connector based on all the best practices of Debezium.
Vitess Connector Deep Dive and Open Source
After we’ve decided to implement our Vitess Connector, we started looking into the implementation details of various Debezium source connectors (MySQL, Postgres, SQLServer), to borrow some ideas. Almost all of them are implemented using a common Connector development framework. So it was clear we should develop the Vitess connector on top of it. We are very active users of the MySql Connector and we benefit from it being open-sourced, as it allows us to contribute to it things we were missing ourselves. So we decided we want to give back to the community and open-source the Vitess source connector code-base under the Debezium umbrella. Please feel free to learn more at Debezium Connector Vitess. We welcome and value any contributions.
At a high level, as you can see below, connector instances are created in Kafka Connect workers. At the time of writing, you have two options to configure the connector to read from Vitess:
Option 1 (recommended):
As shown in Figure 3, each connector captures change events from all shards in a specific keyspace. If the keyspace is not sharded, the connector can still capture change events from the only shard in the keyspace. When it’s the first time that the connector starts, it reads from the current VGTID position of all shards in the keyspace. Because it subscribes to all shards, it continuously captures change events from all shards and sends them to Kafka. It automatically supports the Vitess Reshard operation, there is no data loss, nor duplication.
Figure 3. Each connector subscribes to all shards of a specific keyspace
Option 2:
As shown in Figure 4, each connector instance captures change events from a specific keyspace/shard pair. The connector instance gets the initial (the current) VGTID position of the keyspace/shard pair from VTCtld gRPC, which is another Vitess component. Each connector instance, independently, uses the VGTID it gets to subscribe to VStream gRPC and continuously capture change events from VStream and sends them to Kafka. To support the Vitess Reshard operation, you would need more manual operations.
Figure 4. Each connector subscribes to one shard of a specific keyspace
Internally, each connector task uses a gRPC thread to constantly receive change events from VStream and puts the events into an internal blocking queue. The connector task thread polls events out of the queue and sends them to Kafka, as can be seen in Figure 5.
Figure 5. How each connector task works internally
Replication Challenges
While we were implementing the Vitess Connector and digging deeper into Vitess, we’ve also realized a few challenges.
Vitess Reshard
The Vitess connector supports the Vitess Reshard operation when the connector is configured to subscribe to all shards of a given keyspace. VStream sends a VGTID that contains the shard GTID for all shards. Vitess Resharding is transparent to users. Once it’s completed, Vitess will send the VGTID of the new shards. Therefore, the connector will use the new VGTID after reshard. However, you need to make sure that the connector is up and running when the reshard operation takes place. Especially please check that the offset topic of the connector has the new VGTID before deleting the old shards. This is because in case the old shards are deleted, VStream will not be able to recognize the VGTID from the old shards.
If you decide to subscribe to one shard per connector, the connector does not provide out-of-the-box support for Vitess resharding. One manual workaround to support resharding is creating one new connector per target shard. For example, one new connector for the commerce/-80 shard, and another new connector for the commerce/80- shard. Bear in mind that because they’re new connectors, by default, new topics will be created, however, you could use the Debezium logical topic router to route the records to the same kafka topics.
Offset Management
VStream includes a VGTID event in its response. We save the VGTID as the offset in the Kafka offset topic, so when the connector restarts, we can start from the saved VGTID. However, in rare cases when a transaction includes a huge amount of rows, VStream batches the change events into multiple responses, and only the last response has the VGTID. In such cases, we don’t have the VGTID for every change event we receive. We have a few options to solve this particular issue:
We can buffer all the change events in memory and wait for the last response that contains the VGTID to arrive. So all events will have the correct VGTID associated with them. A few disadvantages are that we’ll have higher latency before events are sent to Kafka. Also, memory usage could potentially increase quite a lot due to buffering. Buffering also adds complexity to the logic. We also have no control over the number of events VStream sends to us.
We can use the latest VGTID we have, which is the VGTID from the previous VStream response. If the connector fails and restarts when processing such a big transaction, it’ll restart from the VGTID of the previous VStream response, thus reprocessing some events. Therefore, it has at-least-once event delivery semantics and it expects the downstream to be idempotent. Since most transactions are not big enough, most VStream responses will have VGTID in the response, so the chance of having duplicates is low. In the end, we chose this approach for its at-least-once delivery guarantee and its design simplicity.
Schema Management
VStream’s response also includes a FIELD event. It’s a special event that contains the schemas of the tables of which the rows are affected. For example, let’s assume we have 2 tables, A and B. If we insert a few rows into table A, the FIELD event will only contain table A’s schema. The VStream is smart enough to only include the FIELD event whenever necessary. For example, when a VStream client reconnects, or when a table’s schema is changed.
The older version of VStream includes only the column type (e.p. Integer, Varchar), no additional information such as whether the column is the primary key, whether the column has a default value, Decimal type’s scale and precision, Enum type’s allowed values, etc.
The newer version (Vitess 8) of VStream starts to include more information on each column. This will help the connector to deserialize more accurately certain types and have a more precise schema in the change events sent to Kafka.
Future Development Work
We can use VStream’s API to start streaming from the latest VGTID position, instead of getting the initial VGTID position from VTCtld gRPC. Doing so would eliminate the dependency from VTCtld.
We don’t support automatically extracting the primary keys from the change events yet. Currently, by default, all change events sent to Kafka have null as the key, unless the message.key.columns connector configuration is specified. Vitess recently added flags of each column in the VStream FIELD event, which allows us to implement this feature soon.
Add support for initial snapshots to capture all existing data before streaming changes.
Summary
MySQL has been used to power most of our backend services at Bolt. Due to the considerable growth of the volume of data and operational complexity, Bolt started to evaluate Vitess for its scalability and its built-in features such as resharding.
To capture data changes from Vitess, as what we’ve been doing with Debezium MySQL Connector, we’ve considered a few options. In the end, we have implemented our own Vitess Connector based on the common Debezium connector framework. While implementing the Vitess connector, we’ve encountered a few challenges. For example, support for the Vitess reshard operation, offset management, and schema management. We reasoned about ways to address the challenges and what we worked out as solutions.
We’ve also received quite some interest from multiple communities in this project and we’ve decided to open-source Vitess Connector under the Debezium umbrella. Please feel free to learn more, and we welcome and value any contributions.
This is my third blog about Stored Procedure support in PostgreSQL, the previous two blogs are reachable from the HighGo CA blogs site https://www.highgo.ca/author/ahsan-h/. The first blog was introduction and usage of Stored Procedures and its difference with Stored Functions, the second blog focussed on creating and using Procedures with Definer and Invoker rights. The purpose of this blog is to demonstrate how to execute a Stored procedure from Java. Java is an important platform for developing enterprise level applications and it is really important to have the capability to call Stored procedure from Java.
Lets start with short intro of Stored Procedures :
“Stored procedure or a Stored function is a module or a program that is stored in the database, it extends the database functionality by creating and reusing user defined programs in supported SQL/PL languages. They can be created in multiple languages (details to follow) and once compiled they become a schema object which can be executed or referenced by multiple applications. The stored procedures/functions are very useful component of a database application as they underpin the complex application logic and database operations that needs to executed and reused multiple times by the database application. Without this feature it would become very complex to carry out database operations that need to repeated, it will be done using several complex SQL queries with round trips in a single function within the database.”
Setup and Configuration
In order to call the stored procedure from Java, you need to have the JAVA development environment setup on your machine. There are plenty of blogs that will show you how to do that, I will just list down the key steps that need to be followed for creating the environment.
Start with installing the JDK on your machine, you can do that by getting the installer from the official site or install it using the package manager. I was doing this on Mac so I did the installation with brew using this command :
Brew install java
After installing JDK on your machine, you need to setup the JAVA_HOME environment variable. The JAVA_HOME is the folder that has the bin directory of JDK, you need to export the JAVA_HOME env variable according your environment, I did the command below after installing openjdk on my machine.
export JAVA_HOME=/usr/local/opt/openjdk
Run the following commands to check that you have Java environment properly set-up on your machine :
Ahsans-MacBook-Pro:java ahsanhadi$ which java
/usr/bin/java
Ahsans-MacBook-Pro:java ahsanhadi$ java -version
openjdk version "15.0.1" 2020-10-20
OpenJDK Runtime Environment (build 15.0.1+9)
OpenJDK 64-Bit Server VM (build 15.0.1+9, mixed mode, sharing)
Ahsans-MacBook-Pro:java ahsanhadi$
You also need to setup the CLASSPATH environment variable, this will tell java where to find all the classes that are being used by your java program
In the CLASSPATH above, I have provided the patch for the PostgreSQL JDBC driver as-well as the JAR file the contains the classes developed for calling Stored procedure from Java. You will see these in later part of the blog.
Download the PostgreSQL JDBC driver from the office site : https://jdbc.postgresql.org/ and place it in a known location so you can specify the in the CLASSPATH as shown above.
The above steps are required in order to get the setup ready in JAVA side of things, let’s move to the database side of things.
Calling Stored Procedure from Java program
Lets start with creating a simple helloworld procedure in the database server and call that from Java.
CREATE OR REPLACE PROCEDURE helloworld() LANGUAGE plpgsql
AS
$$
BEGIN
raise info ‘Hello World’;
END;
$$;
Now lets write the JAVA program that will call this stored procedure :
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.PreparedStatement;
public class HelloWorld
{
private final String url = "jdbc:postgresql://localhost/postgres";
private final String user = "ahsanhadi";
private final String password = "highgo";
/**
* Connect to the PostgreSQL database
*
* @return a Connection object
*/
public Connection connect()
{
Connection conn = null;
try
{
conn = DriverManager.getConnection(url, user, password);
System.out.println("Connected to the PostgreSQL server successfully.");
} catch (SQLException e)
{
System.out.println(e.getMessage());
}
return conn;
}
/**
* @param args the command line arguments
*/
public static void main(String[] args)
{
HelloWorld app = new HelloWorld();
Connection con = app.connect();
try
{
/* CallableStatement stmt = con.prepareCall("{call helloworld()}"); */
PreparedStatement stmt = con.prepareStatement("call helloworld()");
stmt.execute();
System.out.println("Stored Procedure executed successfully");
}
catch(Exception err)
{
System.out.println("An error has occurred.");
System.out.println("See full details below.");
err.printStackTrace();
}
}
}
Here are some key points to note about the above JAVA program :
At the start, we are importing some library classes from the JDBC driver that are being used by the program.
Create instance of String object at the start of the program which will be required for establishing connection with the database server. Please adjust the database server URL, username and password according to your configuration
The connect() method is returning Connection object which is required for making connection with the database server using the given credentials. It uses the DriverManager class and getConnection() method for returning the connection handle of the PG database server.
In the main method of the HelloWorld class, we are making the connection by using the connect().
Using prepareStatement() method of Connection class for making the query command and then using PreparedStatement object to execute the command.
The command used for executing stored procedure is “call HelloWorld()”, it is using empty parenthesis because the procedure doesn’t have any parameters.
Please note that CallableStatement class is used for executing stored procedure from java in Oracle, this is currently not supporting with PG JDBC driver.
Now lets try and execute the HelloWorld java program that we have created :
Ahsans-MacBook-Pro:java ahsanhadi$ java HelloWorld
Connected to the PostgreSQL server successfully.
Stored Procedure executed successfully
Ahsans-MacBook-Pro:java ahsanhadi$
Now lets try to call a procedure that contains an IN parameter :
Create or Replace Procedure call_updstudent (IN st_id INT)
LANGUAGE plpgsql
AS $$
Declare
tot_marks INT;
Begin
-- updating student
call updStudent(3,'5B',true, tot_marks);
raise info 'total marks : %',tot_marks;
END;
$$;
The above procedure takes a IN parameter and call another procedure to perform some DML operations. The calling procedure also returns a INOUT parameter but currently we don’t have a way to get the return value from a stored procedure in PG JDBC, this is currently being implemented.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.CallableStatement;
import java.sql.PreparedStatement;
import java.sql.Types;
/**
*
* @author postgresqltutorial.com
*/
public class CallProc
{
private final String url = "jdbc:postgresql://localhost/postgres";
private final String user = "ahsanhadi";
private final String password = "highgo";
/**
* Connect to the PostgreSQL database
*
* @return a Connection object
*/
public Connection connect()
{
Connection conn = null;
try {
conn = DriverManager.getConnection(url, user, password);
System.out.println("Connected to the PostgreSQL server successfully.");
} catch (SQLException e) {
System.out.println(e.getMessage());
}
return conn;
}
/**
* @param args the command line arguments
*/
public static void main(String[] args)
{
CallProc app = new CallProc();
Connection con = app.connect();
try
{
/* CallableStatement stmt = con.prepareCall("{call helloworld()}"); */
PreparedStatement stmt = con.prepareStatement("call call_updstudent(?)");
stmt.setInt(1,3);
stmt.execute();
stmt.close();
CallableStatement pstmt = con.prepareCall("{? = call getStudentDetail(?)}");
pstmt.registerOutParameter(1, Types.INTEGER);
pstmt.setInt(2,3);
pstmt.execute();
System.out.println("Total Marks : " + pstmt.getInt(1) );
}
catch(Exception err)
{
System.out.println("An error has occurred.");
System.out.println("See full details below.");
err.printStackTrace();
}
}
}
I have added a stored function (shown below) that is also getting called in the above JAVA program. The stored procedure is updating the total marks for the student, the function is returning the marks for the student. So I am call the function after executing stored procedure in order to make sure that the procedure was indeed called and performed the DML.
CREATE OR REPLACE FUNCTION getStudentDetail(IN st_id INT)
RETURNS INT
AS $get_Student$
Declare
st_marks INT;
BEGIN
-- Get student class and marks
select total_marks
INTO
st_marks
From Student
Where std_id = st_id;
return st_marks;
END;
$get_Student$
Language plpgsql;
Running the JAVA program above results in the following output :
Ahsans-MacBook-Pro:java ahsanhadi$ java CallProc
Connected to the PostgreSQL server successfully.
Total Marks : 40
PG JDBC driver limitations
As mentioned earlier, the CallableStatement class should be used for executing stored procedure from JAVA. The prepareCall method of Connection class accept the “Call ProcName()” syntax and returns a CallaableStatement object that is used for executing the stored procedure and returning values for INOUT parameters.
Currently the PG JDBC CallableStatement class doesn’t support calling the stored procedure, if you try to call the procedure using CallableStatement, it will return the following error
org.postgresql.util.PSQLException: ERROR: helloworld() is a procedure
Hint: To call a procedure, use CALL.
Basically the JDBC driver is sending this as select statement to database server and server is returning a meaningful error. The PG JDBC community is currently working on fixing this behaviour.
Conclusion
This is my 3rd blog in the Stored Procedure support in PostgreSQL, this blog should help you in understanding how stored procedures are executed from JAVA and help you write your own JAVA programs for doing the same. I will post an update for this once PG JDBC driver addresses the current limitation stated above.
Ahsan Hadi is a VP of Development with HighGo Software Inc. Prior to coming to HighGo Software, Ahsan had worked at EnterpriseDB as a Senior Director of Product Development, Ahsan worked with EnterpriseDB for 15 years. The flagship product of EnterpriseDB is Postgres Plus Advanced server which is based on Open source PostgreSQL. Ahsan has vast experience with Postgres and has lead the development team at EnterpriseDB for building the core compatibility of adding Oracle compatible layer to EDB’s Postgres Plus Advanced Server. Ahsan has also spent number of years working with development team for adding Horizontal scalability and sharding to Postgres. Initially, he worked with postgres-xc which is multi-master sharded cluster and later worked on managing the development of adding horizontal scalability/sharding to Postgres. Ahsan has also worked a great deal with Postgres foreign data wrapper technology and worked on developing and maintaining FDW’s for several sql and nosql databases like MongoDB, Hadoop and MySQL.
Prior to EnterpriseDB, Ahsan worked for Fusion Technologies as a Senior Project Manager. Fusion Tech was a US based consultancy company, Ahsan lead the team that developed java based job factory responsible for placing items on shelfs at big stores like Walmart. Prior to Fusion technologies, Ahsan worked at British Telecom as a Analyst/Programmer and developed web based database application for network fault monitoring.
Ahsan joined HighGo Software Inc (Canada) in April 2019 and is leading the development teams based in multiple Geo’s, the primary responsibility is community based Postgres development and also developing HighGo Postgres server.
During the last few weeks, the AWS serverless team has been releasing a wave of new features in the build-up to AWS re:Invent 2020. This post recaps some of the most important releases for serverless developers.
We launched Lambda Extensions in preview, enabling you to more easily integrate monitoring, security, and governance tools into Lambda functions. You can also build your own extensions that run code during Lambda lifecycle events, and there is an example extensions repo for starting development.
Lambda launched support for Amazon MQ as an event source. Amazon MQ is a managed broker service for Apache ActiveMQ that simplifies deploying and scaling queues. This integration increases the range of messaging services that customers can use to build serverless applications. The event source operates in a similar way to using Amazon SQS or Amazon Kinesis. In all cases, the Lambda service manages an internal poller to invoke the target Lambda function.
We also released a new layer to make it simpler to integrate Amazon CodeGuru Profiler. This service helps identify the most expensive lines of code in a function and provides recommendations to help reduce cost. With this update, you can enable the profiler by adding the new layer and setting environment variables. There are no changes needed to the custom code in the Lambda function.
Lambda announced support for AWS PrivateLink. This allows you to invoke Lambda functions from a VPC without traversing the public internet. It provides private connectivity between your VPCs and AWS services. By using VPC endpoints to access the Lambda API from your VPC, this can replace the need for an Internet Gateway or NAT Gateway.
For developers building machine learning inferencing, media processing, high performance computing (HPC), scientific simulations, and financial modeling in Lambda, you can now use AVX2 support to help reduce duration and lower cost. By using packages compiled for AVX2 or compiling libraries with the appropriate flags, your code can then benefit from using AVX2 instructions to accelerate computation. In the blog post’s example, enabling AVX2 for an image-processing function increased performance by 32-43%.
Lambda now supports batch windows of up to 5 minutes when using SQS as an event source. This is useful for workloads that are not time-sensitive, allowing developers to reduce the number of Lambda invocations from queues. Additionally, the batch size has been increased from 10 to 10,000. This is now the same as the batch size for Kinesis as an event source, helping Lambda-based applications process more data per invocation.
Code signing is now available for Lambda, using AWS Signer. This allows account administrators to ensure that Lambda functions only accept signed code for deployment. Using signing profiles for functions, this provides granular control over code execution within the Lambda service. You can learn more about using this new feature in the developer documentation.
Amazon EventBridge
You can now use event replay to archive and replay events with Amazon EventBridge. After configuring an archive, EventBridge automatically stores all events or filtered events, based upon event pattern matching logic. You can configure a retention policy for archives to delete events automatically after a specified number of days. Event replay can help with testing new features or changes in your code, or hydrating development or test environments.
EventBridge also launched resource policies that simplify managing access to events across multiple AWS accounts. This expands the use of a policy associated with event buses to authorize API calls. Resource policies provide a powerful mechanism for modeling event buses across multiple account and providing fine-grained access control to EventBridge API actions.
EventBridge announced support for Server-Side Encryption (SSE). Events are encrypted using AES-256 at no additional cost for customers. EventBridge also increased PutEvent quotas to 10,000 transactions per second in US East (N. Virginia), US West (Oregon), and Europe (Ireland). This helps support workloads with high throughput.
AWS Step Functions
Synchronous Express Workflows have been launched for AWS Step Functions, providing a new way to run high-throughput Express Workflows. This feature allows developers to receive workflow responses without needing to poll services or build custom solutions. This is useful for high-volume microservice orchestration and fast compute tasks communicating via HTTPS.
Step Functions now also supports Amazon EKS service integration. This allows you to build workflows with steps that synchronously launch tasks in EKS and wait for a response. In October, the service also announced support for Amazon Athena, so workflows can now query data in your S3 data lakes.
These new integrations help minimize custom code and provide built-in error handling, parameter passing, and applying recommended security settings.
By using sam build --cached, AWS SAM no longer rebuilds functions and layers that have not changed since the last build. Additionally, you can use sam build --parallel to build functions in parallel, instead of sequentially. Both of these new features can substantially reduce the build time of larger applications defined with AWS SAM.
X-Ray now integrates with Amazon S3 to trace upstream requests. If a Lambda function uses the X-Ray SDK, S3 sends tracing headers to downstream event subscribers. With this, you can use the X-Ray service map to view connections between S3 and other services used to process an application request.
AWS CloudFormation
AWS CloudFormation announced support for nested stacks in change sets. This allows you to preview changes in your application and infrastructure across the entire nested stack hierarchy. You can then review those changes before confirming a deployment. This is available in all Regions supporting CloudFormation at no extra charge.
The new CloudFormation modules feature was released on November 24. This helps you develop building blocks with embedded best practices and common patterns that you can reuse in CloudFormation templates. Modules are available in the CloudFormation registry and can be used in the same way as any native resource.
Amazon DynamoDB
You can now use a SQL-compatible query language to perform operations on DynamoDB. This can make it easier for developers to interact with DynamoDB using a familiar query language. You can now also use Kinesis Data Streams to capture item-level changes to your tables, helping you to build advanced streaming capabilities from NoSQL data.
For customers using DynamoDB global tables, you can now use your own encryption keys. While all data in DynamoDB is encrypted by default, this feature enables you to use customer managed keys (CMKs). DynamoDB also announced support for global tables in the Europe (Milan) and Europe (Stockholm) Regions. This feature enables you to scale global applications for local access in workloads running in different Regions and replicate tables for higher availability and disaster recovery (DR).
The DynamoDB service announced the ability to export table data to data lakes in Amazon S3. This enables you to use services like Amazon Athena and AWS Lake Formation to analyze DynamoDB data with no custom code required. This feature does not consume table capacity and does not impact performance and availability. To learn how to use this feature, see this documentation.
You can now use existing Amazon Cognito user pools and identity pools for Amplify projects, making it easier to build new applications for an existing user base. AWS Amplify Console, which provides a fully managed static web hosting service, is now available in the Europe (Milan), Middle East (Bahrain), and Asia Pacific (Hong Kong) Regions. This service makes it simpler to bring automation to deploying and hosting single-page applications and static sites.
AWS AppSync enabled AWS WAF integration, making it easier to protect GraphQL APIs against common web exploits. You can also implement rate-based rules to help slow down brute force attacks. Using AWS Managed Rules for AWS WAF provides a faster way to configure application protection without creating the rules directly. AWS AppSync also recently expanded service availability to the Asia Pacific (Hong Kong), Middle East (Bahrain), and China (Ningxia) Regions, making the service now available in 21 Regions globally.
Still looking for more?
Join the AWS Serverless Developer Advocates on Twitch throughout re:Invent for live Q&A, session recaps, and more! See this page for the full schedule.
For more serverless learning resources, visit Serverless Land.
Unified real-time NoSQL data platform positioned furthest to the right on the Completeness of Vision in the Challenger quadrant
Mountain View, November 30, 2020—Redis Labs, the home of Redis, today announced the company has been named a Challenger in the 2020 Magic Quadrant for Cloud Database Management Systems1. Gartner evaluated Redis Labs for its product Redis Enterprise Cloud among managed cloud database services from 15 additional vendors, with Redis Labs being positioned furthest to the right on the Completeness of Vision in the Challenger quadrant axis.
“We are proud to be positioned as a Challenger in this new Magic Quadrant which analyzes the biggest and most critical market shift happening today––the rapid growth of fully managed cloud database services,” said Ofer Bengal, Co-Founder and CEO at Redis Labs. “We believe Redis Labs is well positioned to shape this market with our focus on delivering a truly unified real-time data platform. By supporting modern data models, across any cloud or hybrid deployment, and underpinning of high-throughput low-latency transactions, Redis Enterprise Cloud is designed for not only today’s traditional database use cases, but also emerging AI/ML processes which require the real-time performance.”
Redis Enterprise Cloud is a cost-effective, fully managed Database-as-a-Service (DBaaS) available on AWS, Microsoft Azure, and Google Cloud. Built on a serverless concept, Redis Enterprise Cloud simplifies and automates database provisioning so software teams can focus on building new innovations, rather than the operational complexity or service availability of their infrastructure. Designed for modern distributed applications, Redis Enterprise Cloud unifies data across any deployment model and the globe, enables seamless migration of datasets, and offers elastically with five-nines availability. Redis Enterprise Cloud delivers these capabilities while maintaining the sub-millisecond performance expected from Redis, at a virtually infinite scale, and offering endless possibilities through native data structures and modern data models.
Download a complimentary copy of the report here. For further perspective on the cloud database market, visit the Redis Labs blog.
1 Gartner, “2020 Magic Quadrant for Cloud Database Management Systems,” Donald Feinberg, Merv Adrian, Rick Greenwald, Adam Ronthal, Henry Cook, 23 November 2020
Gartner Disclaimer
Gartner does not endorse any vendor, product or service depicted in our research publications, and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
About Redis Labs
Data is the lifeline of every business, and Redis Labs helps organizations reimagine how quickly they can process, analyze, make predictions with, and take action on the data they generate. As the home of Redis, the most popular open source database, we provide a competitive edge to global businesses with Redis Enterprise, which delivers superior performance, unmatched reliability, and the best total cost of ownership. Redis Enterprise allows teams to build performance, scalability, security, and growth into their applications. Designed for the cloud-native world, Redis Enterprise uniquely unifies data across hybrid, multi-cloud, and global applications, to maximize your business potential.
Learn how Redis Labs can give you this edge at redislabs.com.
Back in 2019, I wrote about how to create an event store in Redis. I explained that Redis Streams are a good fit for an event store, because they let you store events in an immutable append-only mechanism like a transaction log. Now, with an update of the sample OrderShop application introduced in that blog, I’m going to demonstrate how to use Redis as a message queue, further demonstrating Redis Enterprise’s many use cases beyond caching.
A quick look at microservices, infrastructure services, and distributed systems
Redis is a great solution for creating infrastructure services like message queues and event stores, but there are a few things you need to take into account when using a microservices architecture to create a distributed system. Relational databases were often good for monolithic applications, but only NoSQL databases like Redis can provide the scalability and availability requirements that are needed for a microservices architecture.
Distributed systems imply a distributed state. According to the CAP theorem, a software implementation can deliver only two out of these three attributes: consistency, availability, andpartition tolerance (hence CAP). So, in order to make your implementation fault tolerant, you must choose between availability and consistency. If you choose availability, you’ll end up having eventual consistency, which means that the data will be consistent but only after a period of time has passed. Choosing consistency impacts performance because of the need to synchronize and isolate write operations throughout the distributed system.
Event sourcing, which persists the state of a business entity such as an order, or a customer, as a sequence of state-changing events, goes for availability instead of consistency. It allows write operations to be trivial, but read operations are more costly because, in case they span multiple services, they may require an additional mechanism such as a read model.
Communication in a distributed system can be brokered or brokerless. Brokerless styles are well known, with HTTP as its most famous instance. The brokered approach has, as the name implies, a broker between the sender and the receiver of a message. It decouples the sender and receiver, enabling synchronous and asynchronous communication. This results in more resilient behavior as the message consumer does not have to be available at the moment when the message is sent. Brokered communication also allows independent scaling of sender and receiver.
The “Hello World” of a microservice architecture is the OrderShop, a simple implementation of an e-commerce system using an event-based approach. This sample application uses a simple domain model, but fulfils the application’s purpose.
OrderShop is orchestrated using Docker Compose. All network communication is done over gRPC. The central components are the event store and the message queue: each and every service is connected to and only to them over gRPC. OrderShop is a sample implementation in Python. You can see the OrderShop source code on GitHub.
(Note: This code is not production-ready and is for demo purposes only!)
In this case, the server architecture consists of multiple services. The state is distributed over several domain services but stored in a single event store. The Read model component concentrates the logic for reading and caching the state, as shown here:
The diagram above shows the OrderShop v2 application architecture and data flow.
Commands and queries are communicated via the Message queue component, whereas events are communicated via the Event store component, which also acts as an event bus.
Infrastructure services
In OrderShop v2, all direct communication (asynchronous and synchronous) happens over the Message queue component. For this, I’ll be using Redis Lists, and in particular, two lists combined into a so-called “reliable queue”. It processes simple commands (e.g. single entity operations) synchronously, but long-running ones (e.g. batches, mails) asynchronously and supports responses to synchronous messages out of the box.
The Event store is based on Redis Streams. Domain services (which are just dummies to demonstrate OrderShop’s functionality) are subscribed to event streams named after the event topic (i.e the entity name) and publish events onto these streams. Each event is a stream-entry with the event timestamp acting as the ID. The sum of the published events in the streams results in the state of the overall system.
Application services
The Read model caches deduced entities from the Event store in Redis using the domain model. Disregarding the cache, it’s stateless.
The API gateway is stateless as well, and serves the REST-API on port 5000. It terminates HTTP connections and routes them either to the read model for reading state (queries) or to dedicated domain service for writing state (commands). This conceptual separation between read and write operations is a pattern called Command Query Responsibility Segregation (CQRS).
Domain services
The domain services receive write operations over the Message queue from the API gateway. After successful execution, they publish an event for each of them to the Event store. In contrast, all read operations are handled by the Read model which gets its state from the Event store.
The CRM service (Customer Relation Management service) is stateless—it’s subscribed to domain events from the event store and sends emails to customers using the Mail service.
The central domain entity is the order. It has a field called ‘status’ which transitions are performed using a state machine, as shown in the diagram below.
The diagram above shows the possible states an order can be in.
These transitions are done in several event handlers, which are subscribed to domain events (SAGA pattern), for example:
Clients
Clients are simulated using the Unit testing framework from Python. There are currently 10 unit tests implemented. Take a look at tests/unit.py for further details.
A simple UI is served on port 5000 to watch events and browse state (using WebSockets).
A RedisInsight container is also available to inspect the Redis instance. Open the web browser to http://localhost:8001/ and use redis:6379 to connect to the test database.
The animation above shows RedisInsight, the very powerful Redis GUI.
Conclusion
Redis is not only a powerful tool in the domain layer (e.g. a catalog search) and application layer (e.g. a HTTP session store) but also in the infrastructure layer (e.g. an event store or message queue). Using Redis throughout these layers reduces operational overhead and lets developers reuse technologies they already know.
Take a peek at the code and try your hand at implementing it. I hope this helps demonstrate Redis’ versatility and flexibility in domain and infrastructure services and proves how it can be used beyond caching.
We would like to share that Microsoft has been named a Leader in the 2020 Gartner Magic Quadrant for Cloud Database Management Systems. Our placement is based on our ability to execute and our completeness of vision and is a testament to our ongoing innovation and integration of a broad data portfolio into a cohesive cloud data ecosystem.
Cloud and data technologies have been the focal point of digital transformation as organizations democratize and modernize their data platforms to turn data into a strategic asset. Our customers have shown tremendous resilience as entire industries have shifted under a landscape of economic uncertainty and they rely on Azure for a full range of use cases. Gartner evaluated these use cases across a wide range of industries and deployment sizes for this Magic Quadrant.
Figure 1: Magic Quadrant for Cloud Database Management Systems1
A strong data ecosystem
In the twenty-five years since SQL Server was first released, Microsoft has consistently delivered value to our database customers, starting by building support for operational, business intelligence, and analytical workloads into a single SQL Server product. With the launch of Azure SQL Database in 2010, we brought that same mindset to delivering a fully managed, evergreen database that never needs to be patched or upgraded.
We support customers’ digital transformation through a comprehensive and connected ecosystem that provides a clear path for cloud migration and app modernization. Azure services across the portfolio easily integrate with each other and third-party offerings, expanding capabilities beyond what was possible on-premises. For example, Azure Synapse Analytics combines the best of enterprise data warehousing and Big Data analytics into a unified experience that delivers powerful insights at limitless scale.
Familiar tools and environments between on-premises and Azure mean that our customers can reuse their skills and experience in the cloud. Azure SQL demonstrates this with support for SQL Server workloads over a variety of application patterns, while maintaining the most consistent SQL Server code base of any public cloud.
We’ve further expanded the breadth and depth of our portfolio with multi-model capabilities across data management offerings, making deployment simple and straightforward. Azure Cosmos DB is designed for developers with a wide range of APIs spanning SQL and NoSQL and provides near real-time analytics with Azure Synapse Link. This tighter integration between our analytics and operational databases brings instant clarity and further accelerates new insights for our customers’ businesses.
Global insights and momentum
According to Gartner, the cloud infrastructure and platform services market grew 42 percent year-on-year (2018-2019), with PaaS databases growing 53.8 percent year-on-year over the same period.2 Looking ahead to the next two years, we see accelerated momentum continuing to reshape the data landscape with databases that are truly built for the edge, empowering organizations to store and process their data at or near the collection point including built-in intelligence and analytics. In addition, hybrid multi-cloud scenarios will allow customers to run workloads across on-premises and cloud infrastructures.
Next steps
If you’re ready to harness the power of cloud migration to digitally transform your enterprise, take the next step with the following resources:
1 This graphic was published by Gartner, Inc. as part of a larger research document and should be evaluated in the context of the entire document. The Gartner document is available upon request from Microsoft. Gartner does not endorse any vendor, product or service depicted in its research publications and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
2 “Market Share: Enterprise Public Cloud Services, Worldwide, 2019.” Gartner, Inc.
[This article was first published on business-science.io, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
A year ago I wrote about technologies Data Scientists should focus on based on industry trends. Moving into 2021, these trends remain clear – Organizations want Data Science, Cloud, and Apps. Here’s what’s happening and how Docker plays a part in the essential skills of 2020-2021 and beyond.
There are 3 Key Drivers of changes in technologies:
Rise of Machine Learning (and more generically Data Science) – Unlock Business Insights
Businesses Shifting to the Cloud Services versus On-Premise Infrastructure – Massive Cost Savings and Flexibility Increase
Businesses Shifting to Distributed Applications versus Ad-Hoc Executive Reports – Democratize Data and Improve Decision-Making within the Organization
If you aren’t gaining experience in data science, cloud, and web applications, you are risking your future.
Machine Learning (Point 1)
Data Science is shifting. We already know the importance of Machine Learning. But a NEW CHANGE is happening. Organizations need distributed data science. This requires a new set of skills – Docker, Git, and Apps. (More on this in a minute).
Cloud Services (Point 2)
Last week, I released “Data Science with AWS”. In the article, I spoke about the shift to Cloud Services and the need to learn AWS (No. 6 on Indeed’s Skill Table, 418% Growth). I’ll reiterate – AWS is my Number 1 skill that you must learn going into 2020.
Azure (No. 17, 1107% Growth) is in the same boat along with Google Cloud Platform for Data Scientists in Digital Marketing.
The nice thing about cloud – If you learn one, then you can quickly switch to the others.
Distributed Web Applications (Point 3)
Businesses now need Apps + Cloud. I discuss this at length in this YouTube video.
The Big Change: From 2015 to 2020, apps now essential to business strategy
The landscape of Data Science is changing from reporting to application building:
In 2015 – Businesses need reports to make better decisions
In 2020 – Businesses need apps to empower better decision making at all levels of the organization
This transition is challenging the Data Scientist to learn new technologies to stay relevant…
In fact, it’s no longer sufficient to just know machine learning. We also need to know how to put machine learning into production as quickly as possible to meet the business needs.
To do so, we need to learn from the Programmers the basics of Software Engineering that can help in our quest to unleash data science at scale and unlock business value.
Learning from programmers
Programmers need applications to run no matter where they are deployed, which is the definition of reproducibility.
The programming community has developed amazing tools that help solve this issue of reproducibility for software applications:
It turns out that Data Scientists can use these tools to build apps that work.
We’ll focus on Docker (and DockerHub), and we’ll make a separate article for Git (and GitHub).
What is Docker?
Let’s look at a (Shiny) application to see what Docker does and how it helps.
We can see that application consists of 2 things:
Files – The set of instructions for the app. For a Shiny App this includes an app.R file that contains layout instructions, server control instructions, database instructions, etc
Software – The code external to your files that your application files depend on. For a Shiny App, this is R, Shiny Server, and any libraries your app uses.
Docker “locks down” the Software Environment. This means your software is 100% controlled so that your application uses the same software every time.
Key terminology
Dockerfile
A Dockerfile contains the set of instructions to create a Docker Container. Here’s an example from my Shiny Developer with AWS Course.
A docker container is a stored version of the software environment built – Think of this as a saved state that can be reproduced on any server (or computer).
Docker Containers are a productivity booster. It usually takes 30 minutes or so to build a software environment in Docker, but once built the container can be stored locally or on DockerHub. The Docker Container can then be installed in minutes on a server or computer.
Without Docker Containers, it would take 30 minutes per server/computer to build an equivalent environment.
Key Point: Docker Containers not only save the state of the software environment making apps reproducible, but they also enhance productivity for data scientists trying to meet the ever-changing business needs.
DockerHub
DockerHub is a repository for Docker Containers that have been previously built.
You can install these containers on computers or use these Containers as the base for new containers.
In Shiny Developer with AWS, we use the following application architecture that uses AWS EC2 to create an Ubuntu Linux Server that hosts a Shiny App in the cloud called the Stock Analyzer.
We use a Dockerfile that is based on rocker/shiny-verse:latest version.
We build on top of the “shiny-verse” container to increase the functionality by adding libraries:
mongolite for connecting to NoSQL databases
shiny libraries like shinyjs, shinywidgets to increase shiny functionality
shinyauthr for authentication
We then deploy our “Stock Analyzer” application using this Docker Container called shinyauth. The application gets hosted on our Amazon AWS EC2 instance.
If you are ready to learn how to build and deploy Shiny Applications in the cloud using AWS, then I recommend my NEW 4-Course R-Track System, which includes:
Business Analysis with R (Beginner)
Data Science for Business (Advanced)
Shiny Web Applications (Intermediate)
Expert Shiny Developer with AWS (Advanced) – NEW COURSE!!
I look forward to providing you the best data science for business education.
Matt Dancho
Founder, Business Science
Lead Data Science Instructor, Business Science University
From the very beginning of Slack, MySQL was used as the storage engine for all our data. Slack operated MySQL servers in an active-active configuration. This is the story of how we changed our data storage architecture from the active-active clusters over to Vitess — a horizontal scaling system for MySQL. Vitess is the present and future of Datastores for Slack and continues to be a major success story for us. From the solid scalability fundamentals, developer ergonomics, and the thriving community, our bet on this technology has been instrumental for Slack’s continued growth.
Our migration to Vitess began in 2017 and Vitess now serves 99% of our overall query load. We expect to be fully migrated by the end of 2020. In this post, we will discuss the design considerations and technical challenges that went into choosing and adopting Vitess, as well as an overview of our current Vitess usage.
Availability, performance, and scalability in our datastore layer is critical for Slack. As an example, every message sent in Slack is persisted before it’s sent across the real-time websocket stack and shown to other members of the channel. This means that storage access needs to be very fast and very reliable. In addition to providing a critical foundation for message sending, over the last three years Vitess has given us the flexibility to ship new features with complex data storage needs, including Slack Connect and international data residency. Today, we serve 2.3 million QPS at peak. 2M of those queries are reads and 300K are writes. Our median query latency is 2 ms, and our p99 query latency is 11 ms. The beginning
Slack started as a simple LAMP stack: Linux, Apache, MySQL, and PHP. All our data was stored on three primary database clusters based on MySQL:
Shards: These virtually contained all the customer data tied to using Slack, such as messages, channels, and DMs. The data was partitioned and scaled horizontally by workspace id (a workspace is the specific Slack domain you login into). All the data for a given workspace was stored on the same shard, so the application just needed to connect to that one database.
Metadata cluster: The metadata cluster was used as a lookup table to map a workspace id to the underlying shard id. This means that to find the shard for a particular Slack domain to a workspace, we had to lookup the record in this metadata cluster first.
Kitchen sink cluster: This cluster stored all the other data not tied to a specific workspace, but that was still important Slack functionality. Some examples included the app directory. Any tables that did not have records associated with a workspace id would have gone into this cluster.
The sharding was managed and controlled by ourmonolith application, “webapp”. All data access was managed by webapp, which contained the logic to look up metadata for a given workspace, and then create a connection to the underlying database shard.
From a dataset layout perspective, the company started out using a workspace-sharded model. Each database shard contained all of a workspace’s data, with each shard housing thousands of workspaces and all their data including messages and channels.
From an infrastructure point of view, all those clusterswere made up of one or more shards where each shard was provisioned with at least two MySQL instances located in different datacenters, replicating to each other using asynchronous replication. The image below shows an overview of the original database architecture.
Advantages
There are many advantages to this active-active configuration, which allowed us to successfully scale the service. Some reasons why this worked well for us:
High availability: During normal operations, the application will always prefer to query one of the two sides based on a simple hashing algorithm. When there are failures connecting to one of the hosts, the application could retry a request to the other host without any visible customer impact, since both nodes in a shard can take reads and writes.
High product-development velocity: Designing new features with the model of having all the data for a given workspace stored on a single database host was intuitive, and easily extensible to new product functionality.
Easy to debug: An engineer at Slack could connect a customer report to a database host within minutes. This allowed us to debug problems quickly.
Easy to scale: As more teams signed up for Slack, we could simply provision more database shards for new teams and keep up with the growth. However, there was a fundamental limitation with the scaling model. What if a single team and all of their Slack data doesn’t fit our largest shard?
View into how a single shard is configured with multi-primary replication
Disadvantages
As the company grew, so did the number of product teams working on building new Slack features. We found that our development velocity was slowing down significantly in trying to fit new product features into this very specific sharding scheme. This led to some challenges:
Scale limits: As we onboarded larger and larger individual customers, their designated shard reached the largest available hardware and we were regularly hitting the limits of what that single host could sustain.
Stuck to one data model: As we grew, we launched new products such as Enterprise Grid and Slack Connect, both of which challenge the paradigm that all data for a team will be on the same database shard. This architecture not only added complexity to developing these features, but also a performance penalty in some cases.
Hot spots: We found that we were hitting some major hotspots, while also massively underutilizing the majority of our database fleet. As we grew, we onboarded more and more enterprise customers with large teams, consisting of thousands of Slack users. An unfortunate outcome with this architecture was that we were unable to spread the load of these large customers across the fleet and we ended up with a few hot spots in our database tier. Because it was challenging to split shards and move teams, and difficult to predict Slack usage over time, we over provisioned most of the shards, leaving the long tail underutilized.
Workspace and shard availability concerns: All core features, such as login, messaging, and joining channels, required the database shard that housed the team’s data to be available. This meant that when a database shard experienced an outage, every single customer whose data was on that shard also experienced a full Slack outage. We wanted an architecture where we can both spread the load around to reduce the hot spots, and isolate different workloads so that a unavailable second tier feature couldn’t potentially impact critical features like message sending
Operations: This is a not standard MySQL configuration. It required us to write a significant amount of internal tooling to be able to operate this configuration at scale. In addition, given that in this setup we didn’t have replicas in our topology and the fact that the application routed directly to the database hosts, we couldn’t safely use replicas without reworking our routing logic.
What to do? In the fall of 2016, we were dealing with hundreds of thousands of MySQL queries per second and thousands of sharded MySQL hosts in production. Our application performance teams were regularly running into scaling and performance problems and having to design workarounds for the limitations of the workspace sharded architecture.— we needed a new approach to scale and manage databases for the future.
From the early stages of this project, there was a question looming in our heads: should we evolve our approach in place or replace it? We needed a solution that could provide a flexible sharding model to accommodate new product features and meet our scale and operational requirements.
For example, instead of putting all the messages from every channel and DM on a given workspace into the same shard, we wanted to shard the message data by the unique id of the channel. This would spread the load around much more evenly, as we would no longer be forced to serve all message data for our largest customer on the same database shard.
We still had a strong desire to continue to use MySQL running on our own cloud servers. At the time there were thousands of distinct queries in the application, some of which used MySQL-specific constructs. And at the same time we had years of built up operational practices for deployment, data durability, backups, data warehouse ETL, compliance, and more, all of which were written for MySQL.
This meant that moving away from the relational paradigm (and even from MySQL specifically) would have been a much more disruptive change, which meant we pretty much ruled out NoSQL datastores like DynamoDB or Cassandra, as well as NewSQL like Spanner or CockroachDB.
In addition, historical context is always important to understand how decisions are made. Slack is generally conservative in terms of adopting new technologies, especially for mission-critical parts of our product stack. At the time, we wanted to continue to devote much of our engineering energy to shipping product features, and so the small datastores and infrastructure team valued simple solutions with few moving parts.
A natural way forward could have been to build this new flexible sharding model within our application. Since our application was already involved with database shard routing, we could just bake in the new requirements such as sharding by channel id into that layer. This option was given consideration, and some prototypes were written to explore this idea more fully. It became clear that there was already quite a bit of coupling between the application logic and how the data was stored. It also became apparent that it was going to be time consuming to untangle that problem, while also building the new solution.
For example, something like fetching the count of messages in a channel was tightly coupled to assumptions about what team the channel was on, and many places in our codebase worked around assumptions for organizations with multiple workspaces by checking multiple shards explicitly.
On top of this, building sharding awareness into the application didn’t address any of our operational issues or allow us to use read replicas more effectively. Although it would solve the immediate scaling problems, this approach seemed positioned to run into the very same challenges in the long term. For instance, if a single team’s shard got surprisingly hot on the write path, it was not going to be straightforward to horizontally scale it.
Why Vitess?
Around this time we became aware of the Vitess project. It seemed like a promising technology since at its core, Vitess provides a database clustering system for horizontal scaling of MySQL.
At a high level Vitess ticked all the boxes of our application and operational requirements.
MySQL Core: Vitess is built on top of MySQL, and as a result leverages all the years of reliability, developer understanding, and confidence that comes from using MySQL as the actual data storage and replication engine.
Scalability: Vitess combines many important MySQL features with the scalability of a NoSQL database. Its built-in sharding features lets you flexibly shard and grow your database without adding logic to your application.
Operability: Vitess automatically handles functions like primary failovers and backups. It uses a lock server to track and administer servers, letting your application be blissfully ignorant of database topology. Vitess keeps track of all of the metadata about your cluster configuration so that the cluster view is always up-to-date and consistent for different clients.
Extensibility: Vitess is built 100% in open source using golang with an extensive set of test coverage and a thriving and open developer community. We felt confident that we would be able to make changes as needed to meet Slack’s requirements (which we did!).
Image from SquareCash Vitess blog post. Check out their cool work too!
We decided to build a prototype demonstrating that we can migrate data from our traditional architecture to Vitess and that Vitess would deliver on its promise. Of course, adopting a new datastore at Slack scale is not an easy task. It required a significant amount of effort to set up all the new infrastructure in place.
Our goal was to build a working end-to-end use case of Vitess in production for a small feature: integrating an RSS feed into a Slack channel. It required us to rework many of our operational processes for provisioning deployments, service discovery, backup/restore, topology management, credentials, and more. We also needed to develop new application integration points to route queries to Vitess, a generic backfill system for cloning the existing tables while performing double-writes from the application, and a parallel double-read diffing system so we were sure that the Vitess-powered tables had the same semantics as our legacy databases. However, it was worth it: the application performed correctly using the new system, it had much better performance characteristics, and operating and scaling the cluster was simpler. Equally importantly, Vitess delivered on the promise of resilience and reliability. This initial migration gave us the confidence we needed to continue our investment in the project.
At the same time, it is still important to call out that during this initial prototype and continuing for the years since, we have identified gaps in Vitess in ways that it would not work for some of Slack-specific needs out of the box. As the technology showed promise at solving the core challenges we were facing, we decided it was worth the engineering investment to add-in the missing functionality.
Some key contributions by Slack include:
Today, it is not an overstatement to say that some of the folks in the open source community are an extended part of our team, and since adopting Vitess, Slack has become and continues to be one of the biggest contributors to the open source project.
Now, exactly three years into this migration, we are sitting at 99% of all Slack MySQL traffic having been migrated to Vitess. We are on track to finish the remaining 1% in the next two months. We’ve wanted to share this story for a long time, but we waited until we had full confidence that this project was a success.
Here’s a graph showing the migration progression and a few milestones over the last few years:
There are many other stories to tell in these 3 years of migrations. Going from 0% to 99% adoption also meant going from 0 QPS to the 2.3 M QPS we serve today. Choosing appropriate sharding keys, retrofitting our existing application to work well with Vitess, and changes to operate Vitess at scale were necessary and each step along the way we learned something new. We break down a specific migration of a table that comprises 20% of our overall query load in a case study in Refactoring at Scale, written with Maude Lemaire, a Staff Engineer at Slack. We also plan on writing about our change in migration strategy and technique to move whole shards instead of tables in a future blog post.
Has Vitess at Slack been a success?
Today, we run multiple Vitess clusters with dozens of keyspaces in different geographical regions around the world. Vitess is used by both our main webapp monolith as well as other services. Each keyspace is a logical collection of data that roughly scales by the same factor — number of users, teams, and channels. Say goodbye to only sharding by team, and to team hot-spots! This flexible sharding provided to us by Vitess has allowed us to scale and grow Slack.
During March 2020, as our CEO Stewart Butterfield tweeted, we saw an unprecedented increased usage of Slack as the reality of the COVID-19 pandemic hit the U.S. and work/school shifted out of offices and became distributed. On the datastores side, in just one week we saw query rates increase by 50%. In response to this, we scaled up one of our busiest keyspaces horizontally using Vitess’s splitting workflows. Without resharding and moving to Vitess, we would’ve been unable to scale at all for our largest customers, leading to downtime. As product teams at Slack started writing new services, they were able to use the same storage technology we use for the webapp. Choosing Vitess instead of building a new sharding layer inside our webapp monolith has allowed us to leverage the same technology for all new services at Slack. Vitess is also the storage layer for our International Data Residency product, for which we run Vitess clusters in six total regions. Using Vitess here was instrumental to being able to ship this feature in record time. It enabled our product engineering team to focus on the core business logic, while the actual region locality of the data was abstracted from their efforts. When we chose Vitess, we didn’t expect to be writing new services or shipping a multi-region product, but as a result of Vitess’s suitability and our investment in it over the last few years, we’ve been able to leverage the same storage technology for these new product areas.
Now that the migration is complete, we look forward to leveraging more capabilities of Vitess. We have been already investing in VReplication, a feature that allows you to hook into MySQL replication to materialize different views of your data.
The picture below shows a simplified version of what our Vitess deployment at Slack looks like.
Conclusion
This success still begs the question: Was this the right choice? In Spanish, there is a saying that states: “Como anillo al dedo”. It is often used when a solution fits with great exactitude. We think that even with the benefit of hindsight, Vitess was the right solution for us. This doesn’t mean that if Vitess didn’t exist, we would have not figured out how to scale our datastores. Rather, that with our requirements, we would have landed on a solution that would be very similar to Vitess. In a way, this story is not only about how Slack scaled its datastores. It is also a story that tells the importance of collaboration in our industry.
We wanted to give a shout out to all the people that have contributed to this journey: Alexander Dalal, Ameet Kotian, Andrew Mason, Anju Bansal, Brian Ramos, Chris Sullivan, Daren Seagrave, Deepak Barge, Deepthi Sigireddi, Huiqing Zhou, Josh Varner, Leigh Johnson, Manuel Fontan, Manasi Limbachiya, Malcolm Akinje, Milena Talavera, Mike Demmer, Morgan Jones, Neil Harkins, Paul O’Connor, Paul Tuckfield, Renan Rangel, Ricardo Lorenzo, Richard Bailey, Ryan Park, Sara Bee, Serry Park, Sugu Sougoumarane, V. Brennan and all the others who we probably forgot.
If you’ve built your application on Postgres, you already know why so many people love Postgres.
And if you’re new to Postgres, the list of reasons people love Postgres is loooong—and includes things like: 3 decades of database reliability baked in; rich datatypes; support for custom types; myriad index types from B-tree to GIN to BRIN to GiST; support for JSON and JSONB from early days; constraints; foreign data wrappers; rollups; the geospatial capabilities of the PostGIS extension, and all the innovations that come from the many Postgres extensions.
But what to do if your Postgres database gets very large?
What if all the memory and compute on a single Postgres server can’t meet the needs of your application?
In this post, let’s walk through when you might want to scale out Postgres horizontally. Specifically, when to use Hyperscale (Citus), a built-in deployment option in our Azure Database for PostgreSQL managed service. But first: what exactly is Hyperscale (Citus)?
What is Hyperscale (Citus) in Azure Database for PostgreSQL?
Citus is an open source extension to Postgres that transforms Postgres into a distributed database.
Citus uses sharding and replication to distribute your Postgres tables and queries across multiple machines—parallelizing your workload and enabling you to use the memory, compute, and disk of a multi-machine database cluster.
Hyperscale (Citus) is the integration of the Citus extension with our managed Postgres service on Azure. When you go to provision an Azure Database for PostgreSQL server on the Azure portal, you’ll see Hyperscale (Citus) is one of the built-in deployment options available to you. (See Figure 1 below.) Under the covers, the Citus open source extension is at the core of Hyperscale (Citus).
In short: Hyperscale (Citus) = managed Postgres service on Azure + Citus
Why would you want to use Hyperscale (Citus) to scale out Postgres on Azure?
Performance: Because your single node Postgres is not performant enough and cannot keep up with the peaks in your workload.
Scale: Because your application is growing fast and you want to prepare your Postgres deployment to scale out before you run into performance issues, before you have to send your customers apology letters for poor performance.
Migrating off Oracle: Because you’re migrating off Oracle and you’ve determined that a scaled-out Postgres deployment will best meet your application’s database requirements.
The beauty of Citus is that as far as your app is concerned, you’re still running on top of Postgres. So if you decide to migrate from a single Postgres node to Citus, the good news is you don’t have to re-architect your application. You can generally make the transition to Citus with minimal changes.[] After all, an application running on Citus is still running on Postgres—just, distributed Postgres.
Figure 1: Screenshot of the Azure Portal’s provisioning page for Azure Database for PostgreSQL, showcasing the deployment options, including Hyperscale (Citus).
Why use a managed database service?
Why do so many people run their applications on top of a managed database service?
The primary reason is that by outsourcing database operations, you can focus your time on your application—in terms of new features, bug fixes, refactoring, and adding the kinds of capabilities that make your app more competitive.
I know it seems easy to set up a Postgres server, and it is. You can probably stand one up in 10 minutes or less. But setting up a resilient, production-ready Postgres server takes time and effort. “Production-ready” means you have to architect for backups, high availability, upgrades, hardware issues, security, and monitoring. And even if you have managed your own production Postgres server in the past—managing a distributed Citus cluster is a bit more complicated.
What do I mean? One example is backups. To manage your own backups in Postgres, you have to figure out where to back up to, how to make sure your backup storage is resilient, and how frequently you should backup to meet your RPO (Recovery Point Objective) and RTO (Recovery Time Objective)—and then you have to find a way to automate your backups, too. To manage backups in a distributed Citus cluster, you have to do even more, including making sure you have consistent versions of backups across all your Postgres nodes—hence, more complicated.
A managed database service can make all of this so much easier.
In addition to wanting to outsource the work of managing Postgres in production, another reason why teams use a managed service like Azure Database for PostgreSQL—is time.
Time is, after all, our scarcest resource. Think about it: if you’re lucky, you have about 30K days on this planet.
I point this out because so often when people talk about the value of managed database services, the benefit of a PaaS that often gets overlooked is the opportunity cost. What else could you be doing with your time instead of managing database infrastructure?
Signs you could benefit from Hyperscale (Citus)
Ok, so now you know the primary reasons to scale out Postgres with Hyperscale (Citus) are 1) scale and 2) performance. Often both. But problems with performance and scale manifest in different ways depending on the nature of your workloads. So how do you know if you could benefit from Hyperscale (Citus)?
Here are the 7 signs we often see among teams adopting Hyperscale (Citus):
Database Size is Big: Your database has gotten big, with 100+ GBs of data.[]
Application is Growing: Your application is growing fast in terms of things like number of users, amount of data, amount of concurrent activity, and rollout of new features in your application that add to the workload for your database. Or perhaps you are planning to grow 10X, so you want to prepare for scale now, in advance of the onslaught.
Queries are Getting Slow: Your queries are taking longer and longer. Especially with concurrency. (Note: some of you might run into query performance problems even when you don’t yet have a lot of data. This often happens if you have queries that are compute intensive.)
Nearing Resource Limits of Single Node: Your database resources like memory, CPU, and disk IOPs are getting full—perhaps you’re already on the 2nd largest box, starting to encroach on the limits of what a single Postgres node can do. Think about it: currently, the 2nd-largest Esv3 series VM on Azure has 48 cores with 384GB of memory. By instead provisioning just a 2-node Hyperscale (Citus) cluster with max cores, you can get a total of 128 cores and 864 GB of RAM—plus the ability to add more nodes to your Hyperscale (Citus) cluster when you need to, with zero downtime for the subsequent shard rebalancing.
Affinity for Postgres: You love Postgres. Your team loves Postgres. Or maybe your team is already skilled with Postgres. We also see some users who stick with Postgres because of the Postgres extensions—such as PostGIS for geospatial use cases and HyperLogLog as an approximation algorithm.
Want to buy, and not to build: You want your team to work on the features & capabilities of your application—not on sharding at the application layer, with all of its long-term maintenance costs and headaches.
Want the Benefits of PaaS: You want to adopt a managed database service. And you don’t want to manage hardware, backups, failures, resiliency, updates, upgrades, security, and scaling for a cluster of database servers. If you’ve checked some/many of the boxes above—then adopting Citus as part of a managed database service might be a good fit.
4 examples of common Hyperscale (Citus) use cases
You might be wondering: Is my use case a good fit for Hyperscale (Citus)? Here are 4 example use cases—not an exhaustive list, just a few examples—where Hyperscale (Citus) can help you to improve the scale and performance of your application.
One key characteristic for the first 3 of these use cases is that with Hyperscale (Citus) you can handle a mixture of both transactional & analytical workloads within the same database—at scale. To see how Hyperscale (Citus) performs for mixed workloads (sometimes called HTAP, or hybrid transactional analytical processing), check out this ~15 minute Hyperscale (Citus) demo. The demo uses the HammerDB benchmark to simulate a transactional workload and uses rollups to speed up analytics queries[].
4 examples of use cases that are a fit for Hyperscale (Citus):
Real-time operational analytics (including time series)
Multi-tenant SaaS applications
IOT workloads (that need UPDATEs & JOINs)
High-throughput transactional apps
Real-time operational analytics (including time series)
One of our users described Citus as insanely fast for real-time analytics.
But what does that mean? When we talk about “real-time analytics”, we’re talking about applications that power customer-facing analytics dashboards. Some example applications include things like web and mobile analytics; behavioral analytics via funnel analysis and segmentation; anomaly and fraud detection; and geospatial analytics. The data being analyzed is generally event data or time series data; this time component is why some of these are also called “time series” use cases.
When I first started working with Citus, the key insight for me was to realize that the “customer-facing” aspect is what drives the “real-time” requirement of these dashboards. Because these analytics dashboards are customer-facing, and because the customers are not willing to wait for coffee (and certainly not overnight!) to get responses to their queries, the data needs to be ingested and made available in the dashboard for analysis in real-time. Or at least, in human real-time, which is usually single digit seconds, or sub-second, or even milliseconds.
Here’s a quick checklist you can use to see if you have a real-time analytics workload that is a good fit for Hyperscale (Citus). If you check most of these boxes—not necessarily all, just most—then the answer is YES.
HYPERSCALE (CITUS) CHECKLIST FOR REAL-TIME OPERATIONAL ANALYTICS
Interactive analytics dashboard: You have an interactive analytics dashboard that helps your users visualize and query data.
Lots of concurrent activity: You have lots of users querying the dashboard at the same time (hence: concurrently.) And ingestion and querying are also concurrent—your users need to query the data while you’re simultaneously ingesting new data in real-time.
Demanding performance expectations: Your users need sub-second response times for queries (sometimes millisecond response times) even when handling hundreds of analytical queries per second.
Data needs to be “fresh”: This is the “real-time” bit. Your dashboard needs to continuously ingest and write new data (aka “fresh” data), often at very high throughput to keep up with a stream of events as they happen. Waiting a few days, overnight, or even a few minutes to query data is just not OK for your users.
Large stream of data: Your dashboard needs to ingest and analyze a large stream of data, with millions of events (sometimes billions of events) per day.
Event or time series data: Your data captures the many things that have happened (events) along with their associated timestamps, and you want to analyze the data. Some people call this event data, others call it time series data.
Notable customer stories from teams using Citus for analytics use cases
Helsinki Region Transport Authority: This technical story from the Helsinki Region Transport Authority (HSL) shows what scaling out Postgres horizontally with Hyperscale (Citus) can do. The team at HSL has a pretty interesting application that needed to log real-time location data for thousands of vehicles, match it with timetable data, and display it on a map—in order to enforce SLAs and make sure the people of Helsinki weren’t stranded with unreliable service or unpredictable wait times.
Windows team at Microsoft: Another proof point? The story of the Windows team here at Microsoft who use Citus to scale out Postgres on Azure in order to assess the quality of upcoming Windows releases. The team’s analytics dashboard runs on Citus database clusters with 44 nodes, tracking over 20K types of metrics from over 800M devices (and growing!), fielding over 6 million queries per day, with hundreds of concurrent users querying the dashboard at the same time.
Many Software as a Service (SaaS) applications are multi-tenant. And it turns out that multi-tenant applications can be a really good fit for sharding with Citus, because the customer ID (sometimes called the tenant_id, or account_id) makes for a natural distribution key.[] The notion of tenancy is already built into your data model!
Multi-tenant data models generally require your database to keep all tenant data separate from each other. But if you’re a SaaS provider, you often need to run queries across all the tenants, to understand the behavior of your application and what features are working well or not. Sharding your Postgres database with something like Hyperscale (Citus) gives you the best of both worlds: your customer’s data is kept isolated from other customer data and yet you can still monitor/observe how your application is behaving across all of your customers’s activities.
Here’s a checklist to determine if your SaaS application is a good fit for Hyperscale (Citus). If you check most of these items (you don’t need to check them all) then your SaaS app is likely a fit for Citus.
HYPERSCALE (CITUS) CHECKLIST FOR MULTI-TENANT SAAS:
Tenants need to be kept separate: Your SaaS customers only need to read/write their own data and should not have access to data from your other SaaS customers.
Application is growing fast: Your application is growing fast, in terms of number of users, size of database, or amount of activity—hence the number of monthly active users (MAU) or daily active users (DAU) is increasing.) More specifically, your database is 100s of GBs and growing, your SaaS app has 1000s of customers, you have 100,000+ users (or more.) But these numbers don’t mean that Hyperscale (Citus) is only for large enterprise customers—rather, these numbers mean that Hyperscale (Citus) is for SaaS companies who need to scale, who need to manage growth.
Performance issues, especially with concurrency: You’re starting to run into performance issues during times with lots of concurrency. Perhaps you find yourself turning off some of your analytics features during peak workloads in order to ensure that critical customer transactions are handled right.
Will soon hit resource limits of a single Postgres server: You’re running on a single Postgres server today but it’s the next-to-largest instance size—and you realize you will soon hit the resource limits of a single Postgres server.
Need for cross-tenant queries: You don’t want to give up the ability to run cross-tenant queries for internal monitoring purposes—therefore you don’t want to start using multiple separate databases for different tenants, nor do you want to give up the ability to do JOINS by flipping to a NoSQL database system.
Want to keep relational database semantics: You don’t want to give up foreign keys for referential integrity, nor give up things like database constraints or secondary indexes. So the cost of migrating to a NoSQL data store to get scale is just not worth it to you.
It’s been over 20 years since the term “Internet of Things” (IOT) became part of our lexicon. So long that it’s hard to remember what the world was like before we had sensors everywhere, from doorbells to manufacturing lines to elevators to windmills.
Bottom line all these devices generate a ton of data these days, and all that data needs to be monitored and analyzed. Often with these IOT workloads, the sharding key (aka the distribution column in Citus) ends up being the device ID.
Some IOT applications focus only on the most up-to-date working state of each device (what is the current temperature? when was the last login?) Those IOT applications use UPDATEs in the database, where current state of things (“last known values”) can be continuously updated. Other IOT applications need to store and query historic events (how many device failures happened in the last 3 hours?) and can use append-only databases.
Enabling your IOT application to query both historic events and the current working state of the device (how many failures happened when last known temperature was greater than 90 degrees?) makes for a powerful experience. That means your database needs to handle both updates and JOINs—between, say, your devices table and your events table. Some of the different types of IOT queries you might have:
Aggregate queries, across devices: what’s the total # of devices with a particular attribute or state?
Activity queries for a device: get all the current and historical activity for a given device?
Hierarchical queries: show all the disconnected devices in Building 7
Geospatial queries: show all the devices within a given geographic fenced area?
Why Hyperscale (Citus) for these IOT workloads? Well, first because a relational database like Postgres gives you relational features such as JOINs. And, because Hyperscale (Citus) lets you ingest and query concurrently and at scale. If you’ve read through the other use cases in this post, then you probably see the pattern: by distributing Postgres across multiple servers, Hyperscale (Citus) enables you to parallelize your queries and take advantage of the combined compute, memory, and disk resources of all the servers in the Hyperscale (Citus) server group.
How do you know if your IOT application is a good fit for Hyperscale (Citus)? Here’s a checklist you can start with:
HYPERSCALE (CITUS) CHECKLIST FOR IOT WORKLOADS:
Large numbers of devices: we’ve seen customers with tens of thousands of devices, as well as millions of devices.
Need real-time, high-throughput ingest: In order to manage what’s going on with your fleet of devices, you need the data now. Which means you need a database that can ingest and write with high throughput and low-latency. Example: 2 billion measurements per hour, which equates to roughly ~500,000 measurements ingested per second.
Need concurrency: You may have hundreds of users who need to run queries on this IOT data at the same time.
Query response times in the single digit seconds—or milliseconds: Whether you are managing wind farms or manufacturing devices or fleets of smart meters, one sign that your IOT application could benefit from Hyperscale (Citus) is when your users need their query responses (on fresh data) in the single digit seconds or even in milliseconds. Now. Not in a half hour.
Large database size: Is your database is 100 GB or more (and growing)? We see IOT customers with database sizes from hundreds of GBs to tens of TBs.
High-throughput transactional apps
Some transactional applications are so big in terms of the sheer amount of data, the number of transactions, and the performance expectations—that a single Postgres server cannot meet their needs. But these applications still need the consistency of transactions (not eventual consistency, but strong consistency.) We call these types of applications “high-throughput transactional applications” or “high-throughput OLTP.” It’s not a perfect name, I know—and truth be told some of our developers use a different name to describe this type of workload: “high-performance CRUD.”
Because many of these workloads involve semi-structured data such as JSON—and because Postgres is well known for its JSON capabilities—these high-throughput transactional apps are a good fit for Postgres. Particularly now that Postgres can be distributed with Hyperscale (Citus).
What are the signs that your high-throughput transactional application might be a good fit for Hyperscale (Citus)? Here’s a checklist. If you can check most of these boxes—not necessarily all, just some—then your app is likely a good fit.
HYPERSCALE (CITUS) CHECKLIST FOR HIGH-THROUGHPUT TRANSACTIONAL APPS:
Primarily transactional application: Your app is primarily transactional in nature, with creates, reads, updates, and deletes—without the need for many complex queries.
Semi-structured data like JSON: The objects you’re managing are semi-structured formats like JSON (which Postgres has robust support for.)
Single key: Your workload is mostly based on a single key, which you just have to create, read, update, and delete. (Therefore the majority of your transactions will only need to go to a single shard in the distributed Citus cluster.)
High throughput: Your throughput requirements are demanding and cannot be met by a single database server, on the order of 1000s or 10s of thousands of transactions per second.
Need relational database features: Some teams use NoSQL key-value stores for these types of semi-structured data-intensive workloads—but if you find yourself unwilling to go to NoSQL because there are relational database features you need, then Hyperscale (Citus) might be a good fit. Examples of key relational database features you might want to retain are strong consistency (not that eventual consistency compromise), foreign keys for referential integrity, triggers, and secondary indexes.
Is Hyperscale (Citus) a good fit for you & your application?
When it comes to delivering performance and scale to data-intensive apps, the phrase “it depends” is often bandied about. For good reason. There is no panacea, and it’s always about tradeoffs. I’m hoping the walk through some of the Hyperscale (Citus) use cases—and the checklists—make it easier for you to answer the question of “when to use Hyperscale (Citus) to scale out Postgres?”
In summary, Hyperscale (Citus) gives you the performance and scalability superpowers of the Citus extension combined with all the PaaS benefits of a managed Postgres database service.
And if you’re wondering when you should not use Hyperscale (Citus), well, there are definitely situations where Hyperscale (Citus) is not a fit. The most obvious scenario is when a single Postgres server is sufficient to meet the needs of your application, i.e. when your database fits in memory, performance is snappy, and you’re not faced with the challenges of growth. Another scenario that is not a fit: offline data warehousing—where you run batch offline data loads with lots of complex and custom analytics queries, where you need to analyze TBs of data in a single query, where your data model is not very sharding friendly because you have so many different types of tables and no two tables use the same key. Another scenario where Hyperscale (Citus) is not a fit: where your analytics app doesn’t need to support concurrency.
So if Postgres is your poison and you need more performance and scale than you can eek out of a single Postgres server, you should consider Hyperscale (Citus). Especially if your application is a real-time analytics dashboard, multi-tenant SaaS application, IOT application, or high-throughput OLTP app.
Ways to learn more about Hyperscale (Citus)
To figure out if Hyperscale (Citus) on Azure Database for PostgreSQL is right for you and your app, here are some ways to roll up your sleeves and get started. Since many of you have different learning modes, I’m including a mix of doing, reading, and watching options below. Pick what works best for you!
Download Citus open source packages to try it out locally
Oh, and if you want to stay connected, you can follow our @AzureDBPostgres and @citusdata accounts on Twitter. Plus, we ship a monthly technical Citus Newsletter to our open source community. It’s pretty useful. Here’s an archive of past Citus Newsletters: you can sign up here, too.
If you need help figuring out whether Hyperscale (Citus) is a good fit for your workload, you can always reach out to our Hyperscale (Citus) product team—the team that helped to create Hyperscale (Citus)—via email at Ask AzureDB for PostgreSQL. We’d love to hear from you.
Figure 2: The Citus Elicorn is the mascot for our Citus open source project. Called an “elicorn” because it is part elephant and part unicorn, the Elicorn is a mixture of the Postgres project’s elephant mascot and the magical unicorn. Why a unicorn? Because Citus is kind of magical in how we transform Postgres into a distributed database.
Enjoy what you’re reading?
If you’re interested in reading more posts from our team, sign up for our monthly newsletter and get the latest content delivered straight to your inbox.
Since Covid situation we are – same as the rest of the world – switching most of our MySQL sessions & workshops to the online word. Below you can find the list of events with MySQL recorded sessions we run during the time from September to end of November and also some interesting videos as well. So, the list below includes publicly available recorded MySQL sessions (or slides only) from conferences end other events we attended.
On the link above you can find following sessions:
Tomas Ulin, Vice President, MySQL Engineering, Oracle Mark Leith, MySQL Software Development Director, Oracle at Keynote of “MySQL 8.0: A Giant Leap for SQL”
Nicolai Plum, Database Engineer, Booking.com on “MySQL 8 at Booking.com”
Miguel Araújo, Principal Software Developer, Oracle on “MySQL Shell: The Best MySQL DBA Tool”
Sugu Sougoumarane, Chief Technology Officer, Vitess on “Sharding MySQL with Vitess and Kubernetes”
Rui Quelhas, Principal Software Developer, Oracle on “Developing NodeJS Applications with MySQL 8.0”
Juan Rene Ramirez Monarrez, Software Developer Manager, Oracle on “Migrating to MySQL Database Service: Made Fast and Easy!”
Luís Soares, Software Development Director, Oracle on “MySQL Replication Performance, Efficiency, and the Cloud”
Harin Vadodaria, Principal MTS, Oracle Mike Frank, Product Management Director, MySQL, Oracle on “MySQL Security Model in Oracle Cloud”
Kenny Gryp, MySQL Product Manager, Oracle on “MySQL Database Architectures”
Jesper Wisborg Krogh, Principal Database Reliability Engineer, Okta on “MySQL Performance Tuning”
Fred Descamps at Panel about “SQL or NoSQL? Schema or Schemaless?”
cPanel Live with David Stokes, the Community Manager of MySQL, presenting MySQL 8.0 Changes for DBAs and DevOps, with a live Q&A session, August 12, 2020
Jim Grisanzio talks with MySQL community managers Dave Stokes and Frederic Descamps about the latest news on the project, contributing, and upcoming online events.
Live streaming video with Airton Lastori, the MySQL Principal Product Manager & David Stokes, the MySQL Community Manager talking about MySQL as a leading open-source database management system.
Summary: Things are getting repetitious and that can be boring. Still, looking at lessons from the 90s it’s clear there are at least one or two decades of important economic advances that will based on our current AI/ML. Then some thoughts on where that next really huge breakthrough will come from that will return our initial excitement.
Is AI getting boring? Is it just me or do we seem to be doing the same things over and over again? Let me explain. If you’ve only been in the data science profession for say four or five years then everything no doubt still seems new and exciting. But these days we are well into the age of implementation and we’re definitely on a long plateau in terms of anything transformative.
I hung out my shingle as a data scientist in 2001. Those were pretty bleak days for the art. We only had structured data to work with and the only regular adopters were in direct mail, big finance, and insurance. Every trip to a new prospect started with a long explanation of what data science is (then predictive modeling) and why they needed it. Not that many takers.
But starting with the open source advent of Hadoop in 2008 things really started to bust open. Not all at once of course but now we had unstructured and semi-structured data to work with. Combined with advances in chips, and compute speed thanks to parallelization things like speech recognition, text processing, image classification, and recommenders became real possibilities.
It took the next eight or nine years to fully develop but by 2017 speech and text recognition had reached 95% accuracy, beyond the threshold of human performance. And CNNs were rapidly knocking down the records for image classification. These days who isn’t speaking to Alexa or Siri as a primary interface with their devices?
For many of those years I would trek up to San Jose to the annual Strata conference in March and breathlessly report all the breakthroughs. But in case you didn’t notice, by 2017 all that was through. In 2017 we abandon Hadoop for Spark with its ever more integrated not-only-sequel stack when NoSQL and SQL really did come back together. And by 2018, after Strata I had to report that there we no new eye-catching developments anywhere to be seen.
We saw it coming in 2017 and by 2018 it was official. We’d hit maturity and now our major efforts were aimed at either making sure all our powerful new techniques work well together (converged platforms) or making a buck from those massive VC investments in same.
Now we’re in the age of implementation, learning to apply AI/ML for every dollar that it’s worth. This is actually the most important time because we take our matured toys and apply them with industrial strength to enhance productivity, profits, and the customer experience.
The major advances of the last couple of years are incremental improvements in cloud compute and DNNs, the emergence of automated machine learning (AML), and the maturity of the AI Platform strategy.
Analytic platforms are ever more integrated. Selecting and tuning the best model, and even data prep is much less of a chore. And if you look at the most recent Gartner Magic Quadrant for these platforms practically everyone is now in the upper right quadrant. Everyone’s a winner. Take your pick.
Lessons from the 90’s
The broad adoption of AI/ML and cloud compute are the most powerful economic drivers of the global economy and will likely remain so for at least a decade or two. I along with many VCs have been deeply influenced by Carlota Perez’s short but convincing treatise “Technological Revolutions and Financial Capital”. She makes the academic and historical case for what we see with our own eyes about the power of these two technologies as the primary drivers of economic growth.
If we look back we can see exactly the same thing occurred in the 90s when computerization swept across the global economic scene. At the time we called it ‘automation’ but given what we know now in the age of AI you need to see this as the first wide spread application of computers in business.
There are lots of parallels with what’s going on now. In the early and mid-90s as a director in the consulting practices of the Big 5, we were coming out of a fairly toothless phase of TQM (Total Quality Management) and into the more productive techniques of process improvement. Still no computer automation applied.
In 1993 Thomas Davenport wrote his seminal work “Process Innovation, Reengineering Work through Information Technology” and set us on the road to adding computer automation to everything.
Similar to where we’ve been in AI/ML for the last five years, the methods of reengineering that Davenport espoused required a radical ground-up reimagining of major processes followed by a grueling and expensive usually one to two years of custom development of the then nascent computer automation techniques.
This was all about breaking new ground where no patterns yet existed and only the richest and bravest companies dared lead the way. Failures were rampant.
That sounds a lot like our most recent experiences in AI/ML where the majority of models fail to make it to production. The only good news is that the financial scale of these failures is measured in man weeks of time over a few months instead of armies of programmers spread over 12 to 24 months as was then the case.
Also similar to today, within the space of a few short years vendors began packaging up reusable bits of these computer automated processes and selling them across similar industries. A little up front configuration and you could reuse the solutions that others had paid for.
More important and absolutely parallel to today, the vendors’ programmers (in our case data scientists) maintained and continued to improve the tough bits so investment in scarce human resources was dramatically reduced as was project risk.
Initially these reusable programs were aimed at fairly specific processes like finance, HR, and MRP. But allowing for broader configuration during implementation allowed these industry and process-specific programs to be used across a wider range of cases.
Customer’s actual experience with that initial set up and configuration was typically terrible. It took a long time. It was expensive. Lots of mistakes were made along the way. And once you got it up and running the process had been so expensive, physically grueling, and now so completely integrated into your business that the thought of switching to a competitor’s new and improved platform was almost unthinkable. Good for the vendors. Bad for the customers.
I trust you see where this is going. Eventually these platforms were rolled up into expansive ERPs (enterprise resource planning platforms) now dominated by PeopleSoft, Oracle, SAP, and Workday.
History is our guide. These are the forces at work in the broader AI/ML cloud compute market today. The first in will be difficult to unseat. The next few years will be all about M&A rollups and the battle for share not differentiating on newly discovered techniques.
Where to from Here?
The ERP adoption model from the 90s ran through the early 00s when essentially everyone had one. Curiously that’s almost exactly the time AI/ML got seriously underway. There’s another 10 or 20 years of serious adoption here that will be good for business, good for consumers, and good for many of your careers.
To come back to the original theme though, when and where can we expect the next transformative breakthrough in data science? When can we data scientists really get excited again?
ANNs are not likely to be where it’s at. I’m not alone in that suspicion and many of our best thinkers are wondering if this architecture can continue to incrementally improve. Maybe we need a radical rethink.
The problems are well known. Too much training data. Too much compute. Too much cost and time. And even with techniques like transfer learning the models don’t adapt well to change and can’t transfer deep learning from one system to another.
Assuming that the next great thing has even yet been imagined (perhaps it hasn’t) my bet is on neuromorphic chips. We need to get past the architecture where every neuron is connected to every other neuron and fires every time. It’s not true in human brains so why should it be true in our ANNs.
Also, there’s plenty of evidence and work being done in neuromorphics to use not just the on and off status of a neuron, but also the signal that might be embedded in the string of electrical spikes that occur when our neurons fire. There is probably useful compute or data in the amplitude, number, and time lag between those spikes. We just need to figure it out.
Even once we get good neuromorphic chips, I’m not worried about sentient robots in my life time. Our most advanced thinking about neuromorphics still means they can only learn from what they observe (training) and not that they will be able to invent the imaginary social structures that humans use to cooperate like religions, or nation states, or limited liability corporations.
There are also some techniques in data science that we’ve just passed by. I got my start in data science working with genetic algorithms. Through the first 10 or 15 years of my experience I could get a better model faster every time with an advanced genetic algorithm.
At the time when ANNs were too slow and too compute hungry genetic algorithms briefly were in ascendance. But largely due to commercial indifference and faster, cheaper compute with parallelization ANNs made a comeback. I wouldn’t be too quick to write off techniques like genetic algorithms that closely mimic nature as potential pathways to the future.
Some folks will point at GANs as a way forward. I don’t see it. They can create hypothetically new images and therefore training data but only to the extent that they’ve been trained on existing real world objects. Once again, no potential for a transfer of learning technique in a wholly different object set.
Quantum computing? Maybe. My reading in the area so far is that it does the same things we do now, classification, regression, and the like just a whole lot faster. Also, I think commercial adoption based on sound financial business cases is further down the road than we think.
Still, there is always reason to hope that you and I will be around for the next big breakthrough innovation. Something so startling that it will both knock our socks off and at the same time make us say, oh that’s so obvious, why didn’t I think of that.
Also, there are some very solid and satisfying careers to be made in making the most of what we’ve got. That’s still a very worthwhile contribution.
About the author: Bill is a Contributing Editor for Data Science Central. Bill is also President & Chief Data Scientist at Data-Magnum and has practiced as a data scientist since 2001. His articles have been read more than 2.5 million times.
Machine learning (ML) is becoming more mainstream, but even with the increasing adoption, it’s still in its infancy. For ML to have the broad impact that we think it can have, it has to get easier to do and easier to apply. We launched Amazon SageMaker in 2017 to remove the challenges from each stage of the ML process, making it radically easier and faster for everyday developers and data scientists to build, train, and deploy ML models. SageMaker has made ML model building and scaling more accessible to more people, but there’s a large group of database developers, data analysts, and business analysts who work with databases and data lakes where much of the data used for ML resides. These users still find it too difficult and involved to extract meaningful insights from that data using ML.
This group is typically proficient in SQL but not Python, and must rely on data scientists to build the models needed to add intelligence to applications or derive predictive insights from data. And even when you have the model in hand, there’s a long and involved process to prepare and move data to use the model. The result is that ML isn’t being used as much as it can be.
To meet the needs of this large and growing group of builders, we’re integrating ML into AWS databases, analytics, and business intelligence (BI) services.
AWS customers generate, process, and collect more data than ever to better understand their business landscape, market, and customers. And you don’t just use one type of data store for all your needs. You typically use several types of databases, data warehouses, and data lakes, to fit your use case. Because all these use cases could benefit from ML, we’re adding ML capabilities to our purpose-built databases and analytics services so that database developers, data analysts, and business analysts can train models on their data or add inference results right from their database, without having to export and process their data or write large amounts of ETL code.
Machine Learning for database developers
At re:Invent last year, we announced ML integrated inside Amazon Aurora for developers working with relational databases. Previously, adding ML using data from Aurora to an application was a very complicated process. First, a data scientist had to build and train a model, then write the code to read data from the database. Next, you had to prepare the data so it can be used by the ML model. Then, you called an ML service to run the model, reformat the output for your application, and finally load it into the application.
Now, with a simple SQL query in Aurora, you can add ML to an enterprise application. When you run an ML query in Aurora using SQL, it can directly access a wide variety of ML models from Amazon SageMaker and Amazon Comprehend. The integration between Aurora and each AWS ML service is optimized, delivering up to 100 times better throughput when compared to moving data between Aurora and SageMaker or Amazon Comprehend without this integration. Because the ML model is deployed separately from the database and the application, each can scale up or scale out independently of the other.
In addition to making ML available in relational databases, combining ML with certain types of non-relational database models can also lead to better predictions. For example, database developers use Amazon Neptune, a purpose-built, high-performance graph database, to store complex relationships between data in a graph data model. You can query these graphs for insights and patterns and apply the results to implement capabilities such as product recommendations or fraud detection.
However, human intuition and analyzing individual queries is not enough to discover the full breadth of insights available from large graphs. ML can help, but as was the case with relational databases it requires you to do a significant amount of heavy lifting upfront to prepare the graph data and then select the best ML model to run against that data. The entire process can take weeks.
To help with this, today we announced the general availability of Amazon Neptune ML to provide database developers access to ML purpose-built for graph data. This integration is powered by SageMaker and uses the Deep Graph Library (DGL), a framework for applying deep learning to graph data. It does the hard work of selecting the graph data needed for ML training, automatically choosing the best model for the selected data, exposing ML capabilities via simple graph queries, and providing templates to allow you to customize ML models for advanced scenarios. The following diagram illustrates this workflow.
And because the DGL is purpose-built to run deep learning on graph data, you can improve accuracy of most predictions by over 50% compared to that of traditional ML techniques.
Machine Learning for data analysts
At re:Invent last year, we announced ML integrated inside Amazon Athena for data analysts. With this integration, you can access more than a dozen built-in ML models or use your own models in SageMaker directly from ad-hoc queries in Athena. As a result, you can easily run ad-hoc queries in Athena that use ML to forecast sales, detect suspicious logins, or sort users into customer cohorts.
Similarly, data analysts also want to apply ML to the data in their Amazon Redshift data warehouse. Tens of thousands of customers use Amazon Redshift to process exabytes of data per day. These Amazon Redshift users want to run ML on their data in Amazon Redshift without having to write a single line of Python. Today we announced the preview of Amazon Redshift ML to do just that.
Amazon Redshift now enables you to run ML algorithms on Amazon Redshift data without manually selecting, building, or training an ML model. Amazon Redshift ML works with Amazon SageMaker Autopilot, a service that automatically trains and tunes the best ML models for classification or regression based on your data while allowing full control and visibility.
When you run an ML query in Amazon Redshift, the selected data is securely exported from Amazon Redshift to Amazon Simple Storage Service (Amazon S3). SageMaker Autopilot then performs data cleaning and preprocessing of the training data, automatically creates a model, and applies the best model. All the interactions between Amazon Redshift, Amazon S3, and SageMaker are abstracted away and automatically occur. When the model is trained, it becomes available as a SQL function for you to use. The following diagram illustrates this workflow.
Rackspace Technology – a leading end-to-end multicloud technology services company, and Slalom – a modern consulting firm focused on strategy, technology, and business transformation are both users of Redshift ML in preview.
Nihar Gupta, General Manager for Data Solutions at Rackspace Technology says “At Rackspace Technology, we help companies elevate their AI/ML operationsthe seamless integration with Amazon SageMaker will empower data analysts to use data in new ways, and provide even more insight back to the wider organization.”
And Marcus Bearden, Practice Director at Slalom shared “We hear from our customers that they want to have the skills and tools to get more insight from their data, and Amazon Redshift is a popular cloud data warehouse that many of our customers depend on to power their analytics, the new Amazon Redshift ML feature will make it easier for SQL users to get new types of insight from their data with machine learning, without learning new skills.”
Machine Learning for business analysts
To bring ML to business analysts, we launched new ML capabilities in Amazon QuickSight earlier this year called ML Insights. ML Insights uses SageMaker Autopilot to enable business analysts to perform ML inference on their data and visualize it in BI dashboards with just a few clicks. You can get results for different use cases that require ML, such as anomaly detection to uncover hidden insights by continuously analyzing billions of data points, to do forecasting, to predict growth, and other business trends. In addition, QuickSight can also give you an automatically generated summary in plain language (a capability we call auto-narratives), which interprets and describes what the data in your dashboard means. See the following screenshot for an example.
Customers like Expedia Group, Tata Consultancy Services, and Ricoh Company are already benefiting from ML out of the box with QuickSight. These human-readable narratives enable you to quickly interpret the data in a shared dashboard and focus on the insights that matter most.
In addition, customers have also been interested in asking questions of their business data in plain language and receiving answers in near-real time. Although some BI tools and vendors have attempted to solve this challenge with Natural Language Query (NLQ), the existing approaches require that you first spend months in advance preparing and building a model on a pre-defined set of data, and even then, you still have no way of asking ad hoc questions when those questions require a new calculation that wasn’t pre-defined in the data model. For example, the question “What is our year-over-year growth rate?” requires that “growth rate” be pre-defined as a calculation in the model. With today’s BI tools, you need to work with your BI teams to create and update the model to account for any new calculation or data, which can take days or weeks of effort.
Last week, we announced Amazon QuickSight Q. ‘Q’ gives business analysts the ability to ask any question of all their data and receive an accurate answer in seconds. To ask a question, you simply type it into the QuickSight Q search bar using natural language and business terminology that you’re familiar with. Q uses ML (natural language processing, schema understanding, and semantic parsing for SQL code generation) to automatically generate a data model that understands the meaning of and relationships between business data, so you can get answers to your business questions without waiting weeks for a data model to be built. Because Q eliminates the need to build a data model, you’re also not limited to asking only a specific set of questions. See the following screenshot for an example.
Best Western Hotels & Resorts is a privately-held hotel brand with a global network of approximately 4,700 hotels in over 100 countries and territories worldwide. “With Amazon QuickSight Q, we look forward to enabling our business partners to self-serve their ad hoc questions while reducing the operational overhead on our team for ad hoc requests,” said Joseph Landucci, Senior Manager of Database and Enterprise Analytics at Best Western Hotels & Resorts. “This will allow our partners to get answers to their critical business questions quickly by simply typing and searching their questions in plain language.”
Summary
For ML to have a broad impact, we believe it has to get easier to do and easier to apply. Database developers, data analysts, and business analysts who work with databases and data lakes have found it too difficult and involved to extract meaningful insights from their data using ML. To meet the needs of this large and growing group of builders, we’ve added ML capabilities to our purpose-built databases and analytics services so that database developers, data analysts, and business analysts can all use ML more easily without the need to be an ML expert. These capabilities put ML in the hands of every data professional so that they can get the most value from their data.
About the Authors
Swami Sivasubramanian is Vice President at AWS in charge of all Amazon AI and Machine Learning services. His team’s mission is “to put machine learning capabilities in the hands on every developer and data scientist.” Swami and the AWS AI and ML organization work on all aspects of machine learning, from ML frameworks (Tensorflow, Apache MXNet and PyTorch) and infrastructure, to Amazon SageMaker (an end-to-end service for building, training and deploying ML models in the cloud and at the edge), and finally AI services (Transcribe, Translate, Personalize, Forecast, Rekognition, Textract, Lex, Comprehend, Kendra, etc.) that make it easier for app developers to incorporate ML into their apps with no ML experience required.
Previously, Swami managed AWS’s NoSQL and big data services. He managed the engineering, product management, and operations for AWS database services that are the foundational building blocks for AWS: DynamoDB, Amazon ElastiCache (in-memory engines), Amazon QuickSight, and a few other big data services in the works. Swami has been awarded more than 250 patents, authored 40 referred scientific papers and journals, and participates in several academic circles and conferences.
Herain Oberoi leads Product Marketing for AWS’s Databases, Analytics, BI, and Blockchain services. His team is responsible for helping customers learn about, adopt, and successfully use AWS services. Prior to AWS, he held various product management and marketing leadership roles at Microsoft and a successful startup that was later acquired by BEA Systems. When he’s not working, he enjoys spending time with his family, gardening, and exercising.
In many enterprises, DevOps teams are leading the push toward digital transformation. This journey often begins with application and infrastructure modernization efforts designed to unlock the potential of the digital economy and confront competition that’s only a click away. Application performance lags of just a few seconds can have enormous downstream impact on the customer experience and ultimately the business’ success. For example, if the Gap app doesn’t load instantly or doesn’t give inventory updates within a few seconds, many shoppers won’t hesitate to buy their khakis somewhere else. Simply put, the application’s data processing must be fast enough to keep up with consumers’ demand for real-time performance.
According to an Allied Market Research report, the global NoSQL database market is estimated to reach $22.08 billion by 2026. An increase in unstructured data, demand for real-time data analytics and a surge in application development activities across the globe are the driving factors. Traditional relational databases are often too slow and simply can’t match today’s web-scale demands. They were designed with the intention of scaling vertically and on a single node. Modern distributed, non-relational NoSQL databases were designed from the start to be multi-node and scale horizontally, allowing enterprises to be more agile.
DevOps database requirements
NoSQL databases are perfectly suited for the flexible data storage and manipulation needs of developers and operations teams. DevOps embraces a vision of enterprise technology that integrates traditionally siloed development, operations, and quality assurance departments.Emphasizing communication and cooperation among the various components, DevOps teams focus on ways to automate and integrate development, quality testing, and production of applications and services to reduce their time-to-market.
DevOps teams strive to deploy and manage their databases just like they do application code. Changes to databases are recognized as just another code deployment to be managed, tested, automated, and improved with the same kind of seamless, robust, reliable methodologies applied to application code. Databases are now part of the continuous integration/continuous deployment (CI/CD) pipeline. If the DevOps pipeline doesn’t include the database, it becomes a bottleneck slowing delivery of new features. In fact, DevOps teams integrate databases not only in the development pipeline but also in the overall release pipeline.
Forward-thinking DevOps teams designing applications, including the data layer, seek to satisfy a number of critical requirements:
Operational flexibility (run in the cloud, on-premises, and in hybrid deployments)
Operational simplicity
True high availability and resiliency
Unlimited scalability and high performance
Platform agnostic
Global distribution with local latencies for writes and reads
Lower total cost of ownership (TCO)
Redis has become a popular database choice due to its ease of implementation and exceptionally high performance, among other benefits. Most real-time data eventually lands in Redis because of its impressively low latency (less than 1 millisecond). The highest-performing NoSQL database, Redis delivers up to 8 times the throughput and up to 80% lower latency than other NoSQL databases. Redis has also been benchmarked at 1.5 million operations/second at sub-millisecond latencies while running on a single, modest cloud instance. In Datadog’s 2020 Container Report, Redis was the most-popular container image in Kubernetes StatefulSets.
Redis fits very well into the DevOps model due to its ease of deployment, rigorous unit and functionality testing of core and supplementary Redis technology, and ease of automation through tools such as Docker, Ansible, and Puppet. Redis Enterprise is an enterprise-grade, distributed, in-memory NoSQL database server, fully compatible with open source Redis. Redis Enterprise extends open source Redis and delivers stable high performance, zero-downtime linear scaling and high availability. It is uniquely positioned to help DevOps teams meet their goals with less management toil and lower overhead.
Why DevOps teams choose Redis Enterprise
So what, exactly, are DevOps teams looking for in Redis Enterprise? Here are the five most important capabilities:
Five-nines (99.999%) uptime
Flexible deployment options
Virtually unlimited linear scalability and high performance
Global distribution (with Active-Active geo-distribution)
Multi-tenant architecture
Five-nines (99.999%) uptime
High availability is the holy grail for most DevOps teams, and they often spend immense amounts of time and money to keep their applications running. But failing to recover from a database failure in a timely manner may result in losing data and millions of operations. Redis Enterprise offers uninterrupted high availability, completely transparent to the DevOps team, with diskless replication, instant failure detection, and single-digit-seconds failover across racks, zones, and geographies. It delivers high throughput and low latency even during cluster-change operations such as adding new nodes to the cluster, upgrading software, rebalancing, and re-sharding data.
This unique combination of high-availability technologies guarantees four-nines (99.99%) uptime and five-nines (99.999%) uptime in Active-Active deployments of globally distributed databases. Active-Active geo distribution enables simultaneous read and write operations on the same dataset across multiple geographic locations. Using academically proven conflict-free replicated data types (CRDTs) technology, Redis Enterprise automatically resolves conflicting writes, without changing the way your application uses Redis. It enables a disaster-proof architecture for geo-distributed applications, while also delivering local latency.
Flexible deployment options
Redis Enterprise has flexible deployment options.
In the current technology landscape, the amount of choice available when it comes to platforms is simply astonishing.It’s practically impossible to take the time to investigate every option, so enterprises often stick to platforms that they’re comfortable with, even if they aren’t necessarily the best tools for the task. Part of successfully implementing DevOps involves choosing the best platforms for the unique context of your organization’s environment and the nature of your processes. That’s exactly why Redis Enterprise takes a platform-agnostic stance towards DevOps.
Redis Enterprise provides a tightly integrated solution with the VMware Tanzu application service. Application developers can natively use the Redis Enterprise Service Broker for VMware Tanzu for launching and managing the lifecycle of their databases/cache systems, and operators can employ a variety of automation tools for managing their Redis deployments with enhanced monitoring capabilities, failure recovery, seamless migration between plans, and seamless software upgrades.(Learn more about the benefits of Redis Enterprise in your Tanzu environment in Pivotal’s Redis Enterprise for VMware Tanzu documentation,)
Redis Enterprise is also a great way to bring more power and flexibility to the CI/CD process. Redis can help distributed development teams release new features safely and roll them back with minimal impact when required.. Learn more about how feature toggles, feature context and error logs can enhance your CI/CD process in this blog post.)
3. Virtually unlimited scalability and high performance
In today’s fast-paced development environment, a well-thought-out preparation strategy for scalability is a must to make the process smooth and easy. Many DevOps failures occur because the underlying infrastructure is unable to scale to meet demand, causing the application to crash. That’s a real issue, because scaling database solutions requires massive additional infrastructure investments as they accrue non-linear overhead in scaled-out environments.
Linear scaling, which means that to get 2x the performance you need roughly 2x the infrastructure, 4x performance demands approximately 4x the infrastructure, and so on, is critical to enable DevOps teams to affordably keep up with fast-growing requirements. Made for DevOps environments, Redis Enterprise fuels businesses that want to rapidly deploy dynamic apps to millions of users at a time. (Learn more about linear scalability in Redis Enterprise here.)
4. Global distribution (with Active-Active geo distribution)
DevOps teams deploy applications that are increasingly built using microservices. These apps leverage a multitude of different component parts, with different approaches to infrastructure, hosted in a variety of different locations, consumed by people everywhere, and distributed on many different platforms.
To support the responsiveness and scalability required by distributed applications, DevOps teams are increasingly looking to innovative database technologies such as geo-distributed data processing to deliver highly interactive, scalable, and low-latency geo-distributed apps. Many are choosing Redis Enterprise as a modern database that can be deployed globally yet provides local latencies for writes and reads, while simplifying resolution of conflicts and enabling strong eventual consistency for datasets.
Whether your environment includes applications running on-premises, in a hybrid cloud, or on multiple clouds—or on a mix of all three—Redis Enterprise’s Active-Active geo distribution promotes high availability and low latency. With built-in active-active database technology based on CRDTs, Redis Enterprise helps DevOps teams achieve high performance across distributed datasets. This significantly reduces the development effort involved in building modern applications that deliver local latencies even when they need to span racks, clouds, or regions.
5. Multi-tenant architecture
Multi-tenancy in Redis Enterprise.
In a multi-tenant software architecture, a single instance of a software application(including database) serves multiple tenants . Each tenant’s data is isolated from other tenants sharing the application instance. This ensures data security and privacy for all tenants. When choosing a database for multi-tenant applications, developers have to strike a balance between customers’ need or desire for data isolation and a solution that scales quickly and affordably in response to growth or spikes in application traffic. Hence, to ensure complete isolation, the developer can allocate a separate database instance for each tenant; at the other extreme, to ensure maximum scalability, the developer can have all tenants share the same database instance.
Most developers opt to use Redis Enterprise because it offers software multi-tenancy support. A single deployment of Redis Enterprise Software (often deployed as a cluster of nodes) serves hundreds of tenants. Each tenant has its own Redis database endpoint which is completely isolated from the other Redis databases. As shown in the diagram on the left, there are multiple databases like DB1 for storing JSON data, DB2 for search and filtering, DB3 for storing and analyzing time series and so on.
Redis Enterprise + DevOps
Rapid deployment is a key element of a successful DevOps approach. Redis Enterprise provides a fast database that helps DevOps teams more efficiently build and operate applications. Redis’ easy-to-learn data structures and modules are flexible enough to cover a variety of use cases—and Redis Enterprise features such as persistent-memory storage and shared-nothing cluster architecture help reduce operational burden. That’s why DevOps teams love Redis as much as developers do.
PostgreSQL is the World’s most advanced Open Source Relational Database. The interview series “PostgreSQL Person of the Week” presents the people who make the project what it is today. Read all interviews here.
Please tell us about yourself, and where you are from.
I’m originally from Pennsylvania but moved to Maryland around 2000 and have lived here ever since. I’ve been a Senior Database Engineer with CrunchyData for almost 4 years now.
Keith Fiske
How do you spend your free time? What are your hobbies?
I’m an avid video and board game player and enjoy not just playing games at home but traveling to events around the country involving them (meetups, conferences, etc). I got a motorcycle a few years ago and enjoy taking trips around the area with local riding groups. In the last few years I’ve also grown quite a collection of one of my favorite toys growing up: Lego.I’m more a fan of building the sets than making my own creations. And now that I have the means to buy some of the bigger sets I could never have as a kid, it’s something I have to be very careful I don’t spend too much money on when I see something that really triggers that nostalgia.
Any Social Media channels of yours we should be aware of?
Last book you read? Or a book you want to recommend to readers?
Currently reading some of the newer stories in Neil Gaiman’s Sandman Universe. And lately I’ve been reading anything new that comes out from Peter F. Hamilton. Highly recommend him to any science fiction fans.
Latest movie you saw? Current tv shows you are watching?
Latest movie I saw was Tenet
Currently watching The Expanse, Mandelorian and My Hero Academia
I honestly don’t watch nearly as much tv as I used to either. My current primary form of entertainment is actually Twitch.tv. Being able to interact with people, especially being stuck at home so much more lately, is a lot more enjoyable than just sitting there passively watching things.
How would your ideal weekend look like?
I don’t really have one particular ideal. I’d be just as happy going for a bike ride (motorcycle or bicycle) as I would staying home playing video games or having some friends over for board games.
What’s still on your bucket list?
Mostly just traveling to places around the world just to be able to say I’ve been there. Even more motivated to do that now that I’ve been stuck at home for nearly a year without being able to travel.
When did you start using PostgreSQL, and why?
At a previous job we needed to find a new ticketing system to use. I’d been playing around with MySQL a lot with WordPress and some other web applications, but at the time I was interested in trying something new. We’d settled on OTRS and I saw it supported PostgreSQL so I figured I’d give it a try.
Do you remember which version of PostgreSQL you started with?
It was either 8.2 or 8.3.
Have you studied at a university? If yes, was it related to computers? Did your study help you with your current job?
Yes, but it was stretched out over quite a long period of time due to work and other commitments. I ended up with an Associates in Computer Science. I can say that it did help me quite a bit since I was able to pick some courses that directly related to the work I was doing at the time and I still recall some of those fundamentals being relevant today.
What other databases are you using? Which one is your favorite?
I don’t use any other databases besides PostgreSQL too extensively. I do use Redis as a caching server in Nextcloud, but that’s about it.
On which PostgreSQL-related projects are you currently working? How do you contribute to PostgreSQL?
pg_partman
has been my biggest project that I’ve worked on and still maintain. I’ve also been working on a monitoring platform called pgMonitor
. I center its development around PostgreSQL monitoring, but there’s nothing stopping it from being used to monitor anything since it’s using already existing monitoring utilities (Prometheus & Grafana). I’ve also been helping to develop some high availability solutions for PostgreSQL using Patroni & Ansible. I also work on many other small projects around PostgreSQL and that is what I enjoy doing the most. Some others are, pg_bloat_check
, PGExtractor
& pg_jobmon
. I’ve got many other ideas for small tools if only I had the time to work on them.
Any contributions to PostgreSQL which do not involve writing code?
I enjoy doing training and classes to teach people how to use PostgreSQL. I also regularly attend and speak at conferences and local meetups.
What is your favorite PostgreSQL extension?
pg_partman of course.
Outside of my own, pg_stat_statements
and pgstattuple
from contrib. Outside of contrib, I’ve never gotten to use it yet myself, but PostGIS
has always really impressed me.
What is the most annoying PostgreSQL thing you can think of? And any chance to fix it?
No global indexes. It’s beyond my current ability to be able to contribute any fixes for it, and I’ve heard it is not an easy problem to solve.
What feature/mechanism would you like to see in PostgreSQL? And why?
The pluggable storage mechanisms that are currently in the works are probably what I’m looking forward to seeing the most right now. The JSON datatype really opened up PostgreSQL’s usability in the NoSQL world. I think the pluggable storage will do some really amazing things for its current scalability concerns.
Could you describe your PostgreSQL development toolbox?
I’m a very simple person on this topic. Just vim (without any really fancy plugins) or any plain text editor as long as it has syntax highlighting. Since I do a lot of plpgsql work, the pgTAP
testing suite is probably one of my most used tools when working on extensions.
Which PostgreSQL conferences do you visit? Do you submit talks?
PGCon
and PostgresOpen
are the two I regularly attend that are part of the regular PG circuit. I also submit regularly to SCaLE
(Southern California Linux Expo) and All Things Open. Locally I attend the Baltimore & DC PG Meetups as well as CALUG (Columbia Area Linux Users Group). If I have any talk ideas, I definitely submit them wherever I can.
Do you think Postgres has a high entry barrier?
I do. But I think that’s the case with any project that is primarily maintained by engineers and doesn’t have any sort of dedicated team whose primary goal is trying to solve that entry barrier issue. That’s not to say we don’t have people in the community that are trying to do that, because we most certainly do. But a team of volunteers is a lot different than a team who’s sole, paid profession is documentation, ease-of-use, and marketing. Once you can get past that initial barrier, though, I think it is far more user friendly for people that just need a reliable database to get their work done.
What is your advice for people who want to start PostgreSQL developing – as in, contributing to the project. Where and how should they start?
I would say one of the best ways to get started is to attend a meetup group or conference that happens to be in your area. While I did take some initiative to try and learn it myself when the opportunity presented itself at my job, I would say attending the PG East conference in NYC many years ago is what really got me pulled into the community and development. Not only did I get to meet people I’d seen in passing on mailing lists trying to get support, it’s how I got my first job as a dedicated DBA!
Do you think PostgreSQL will be here for many years in the future?
Most definitely.
Would you recommend Postgres for business, or for side projects?
Both.
Are you reading the -hackers mailinglist? Any other list?
I try to keep an eye on the novice, -general
and administrative mailing lists myself since I’m not deep into working on the PG backend. I do definitely take advantage of the access to the core team that the hackers mailing list provides. I think that access is one of PostgreSQL’s strengths.
Which other Open Source projects are you involved or interested in?
I’m a heavy user of Nextcloud and have been using it since it used to be Owncloud. It’s by far one of the most useful web applications I’ve ever come across for managing data syncing, sharing and backups.
MySQL Cluster is a real time, ACID-compliant transactional database. It is a combination of MySQL server and the NDB storage engine. Data is cached in memory and durably stored on disk. Indexed columns are always kept in memory while non-indexed columns can be kept in memory or disk. It was mainly designed for telecom databases with 99.999% availability and high performance. Unlike simpler sharded systems, MySQL Cluster transactions can transparently query and update all data in the system.
Key features of MySQL Cluster:
MySQL Cluster is designed using a shared nothing architecture
Support for large database sizes
With all columns kept in memory, can store upto few terabytes
With some columns kept on disk, can store upto few petabytes
Supports read and write transactions:
during upgrade, scaling out, adding new columns/index to the
tables, backup, add new nodes, add/drop FK etc
Survives multiple node failures while writes happen.
Support for automated node failure detection and automated
recovery after node failure.
Support for 144 data nodes (version 8.0.18 or later).
Support for multiple levels of replication:
Synchronous replication inside the cluster (replica)
Asynchronous replication between cluster (Source -> Replica)
Support for both SQL and NoSQL (NDB API) i.e. in both ways user
applications can interact with the same data.
Support for online scaling with no down time, i.e. cluster can be scaled
while transactions are going on.
Support for automatic data partitioning based on cluster architecture
selected by the user.
Cluster architectural diagram:
Components of MySQL cluster in nutshell:
From the above architectural diagram, one can see that there are three
types of nodes exist. These are:
Management node(s)
Data nodes
API nodes
Management nodes:
This node has a number of functions including:
Handling the cluster configuration file called ‘config.ini’ and serving
this info to other nodes on request.
Serves cluster address and port information to clients.
Gathers and records aggregated cluster event logs.
Provides a cluster status query and management service, available to
users via a Management client tool.
Acts as an arbitrator in certain network partition scenarios.
Management nodes are essential for bootstrapping a system and
managing it in operation, but they are not critical to transaction
processing, which requires only Data nodes and Api nodes.
Since this server has limited responsibilities it does not need a lot of
resources to run.
Data nodes:
These are the heart of MySQL cluster storing the actual data and indexes,
and processing distributed transactions. Almost all of the cluster
functionality are implemented by these nodes. Data nodes are logically
grouped into nodegroups. All data nodes in a nodegroup (up to four)
contain the same data, kept in sync at all times. Different nodegroups
contain different data. This allows a single cluster to provide high
avilability and scale out of data storage and transaction processing
capacity. Data nodes are internally scalable and can make good use of
machines with large resources like CPU, RAM, Disk capacity etc.
API nodes:
Each API node connects to all of the data nodes. API nodes are the point
of access to the system for user transactions. User transactions are
defined and sent to data nodes which process them and send results back.
The most commonly used API node is MySQL server (mysqld) which
allows SQL access to data stored in the cluster.
There are a number of different API node interfaces MySQL cluster
supports like C++ NDB API, ClusterJ (for java applications), Node.js
(for java script applications) etc.
Use cases of MySQL Cluster:
MySQl cluster was initially designed for telecom databases. After years of
improvement, it is now used in many other areas like online gaming,
authentication services, online banking services, payment services,
fraud detection and many more.
Performance:
NDB is known for its high performance:
20M writes/second
200M reads/second
1B updates/minute in benchmarks
limitation:
Like every database, MySQl Cluster has some limitations which includes:
Only READ COMMITTED transaction isolation level is supported
No support for save point
GTID (Global Transaction Identifiers) not supported
No schema changes (DDL) allowed during data node restart
For more information about MySQL NDB Cluster, Please check the official
documentation site.
MariaDB Xpand, MariaDB’s new distributed SQL smart engine, has now been released as GA! With the GA release of Xpand, included with MariaDB Enterprise Server 10.5.8-5, we bring the power of distributed SQL into the MariaDB family of products and make it accessible to all our users through the MariaDB Platform. With this release, you can now access Xpand like any of our other storage engines through MariaDB Enterprise Server by using the standard ENGINE=XPAND syntax. For a more detailed description of Xpand, check out our documentation.
Making Xpand available as a storage engine option on MariaDB Enterprise Server brings you the elasticity and scalability of NoSQL with the transactional integrity of SQL without requiring you to restructure your application. The Xpand smart engine adds several unique and groundbreaking features to MariaDB, some of which are highlighted below.
Distributed Everything
Xpand was built from the start with multi-node and a shared-nothing architecture in mind. By default, everything is distributed: tables, indices, lock management, transaction processing etc. The distributed multi-node architecture in concert with automatic data redundancy provides built-in HA (high availability), and ensures that Xpand can handle individual node failures gracefully and transparently.
The query processing is also distributed, even joins are distributed. Execution plans are compiled and then executed locally on each node as opposed to having a central manager for the query execution. And since everything that is distributed can be done in parallel, it gives Xpand linear scalability for both reads and writes.
Automatic Rebalancing
Automatic rebalancing is one of the coolest features of Xpand and unique in the universe of distributed SQL databases. The rebalancer is responsible for ensuring that the data is evenly balanced across the nodes. This process happens automatically and transparently in the background and is triggered when the process detects changes in node counts or uneven workloads. When nodes are added to or removed from the Xpand deployment, the rebalancer will kick in and redistribute data behind the scenes to ensure the nodes are used evenly. Even without any changes to the node count, the rebalancer ensures the nodes are evenly used. If the data is somehow skewed so that some nodes end up being used more than others, the rebalancer will notice and redistribute the data to ensure a more even load.
Consistency Model and Advanced SQL
Xpand has very advanced SQL features. The great thing with Xpand is that all SQL is by default fully ACID and has strict consistency. You cannot read inconsistent data by mistake.
In addition to this, Xpand has a multi-version concurrency control (MVCC) model that allows you to read data as a snapshot in the default isolation level (i.e. REPEATABLE READ). Perhaps the most interesting part of all this is that DDL in Xpand is transactional and non-locking. This means that if you run an ALTER TABLE on a large table and the operation takes a while to complete, all other transactions can still access your table during the operation. The table is fully available at all times, despite your long-running ALTER TABLE. This is something unique that no other storage engines in MariaDB offer currently.
The GA release of Xpand is a very exciting development for MariaDB adding a whole new level of versatility for customers with extreme scaling or availability needs.
For More Information
For a more complete list of the Xpand features please check out our Documentation which has been updated for the Xpand GA release.
You can also try MariaDB SkySQL to check out Xpand as a tech preview in the cloud with no need to install anything.
Xpand is available to MariaDB Platform subscribers. Any nodes can be converted to Xpand nodes without additional cost, please contact your MariaDB sales representative.
You now can use PartiQL with NoSQL Workbench to run SQL-compatible queries on your DynamoDB data. PartiQL makes it easier to interact with DynamoDB, and now you can use PartiQL to query, insert, update, and delete table data by using NoSQL Workbench.
Let’s reflect on the many exciting things that did happen to make this year both impactful and memorable.
Big News for Neo4j
Neo4j Named a Leader in Graph Data Platforms by Independent Research Firm
Neo4j was recognized as a leader in The Forrester Wave for Graph Data Platforms, Q4 2020. Of the 12 graph data platform providers recognized, Neo4j achieved the highest possible scores in 17 of the 27 critical criteria used for evaluation. The report is designed to help enterprise architecture professionals select the right graph data platform for their needs, sharing how organizations can apply this powerful technology to solve complex data and analytics problems.
The Future of Graph Databases is Here: Introducing Neo4j 4.0
The release of the Neo4j 4.0 – one of our biggest releases to date – addressed the broad and complex challenges of application development in the decade to come, including unlimited scalability, intelligent data context and robust enterprise-grade security. This update enabled enterprises to build intelligent applications that leverage the increasingly dynamic, interconnected nature of data.
Analyzing the FinCEN Files with Neo4j
In September, the International Consortium of Investigative Journalists (ICIJ) exposed a vast network of industrial-scale money laundering running through Western banks and generally ignored by U.S. regulators – and they used Neo4j to help crack the case wide open.
The global investigation, dubbed the FinCEN Files, reveals how money launderers move their dirty money. Emilia Díaz Struck, ICIJ’s research editor and Latin American coordinator, spoke to diginomica about the role graph databases played in untangling the complex data associated with the FinCEN files.
“The way we use graph databases is always the same: to find hidden connections that are not obvious. If you find a shareholder or a person, could this person also actually be this person or entity you’ve seen over here, and so be connected to more things I’m not seeing yet. Whenever you have vast amounts of data, your risk is missing what is there; technology and machine learning, things like graph databases, allow you to see things that sometimes could take you years as a human.”
Ecosystem + Cloud
Neo4j Delivers First and Only Integrated Graph Database Service on Google Cloud Platform
Neo4j Aura Professional was made available on Google Cloud Platform in August as a fully integrated graph database service on the Google Cloud Marketplace. As a self-service solution, Neo4j Aura Professional is designed for small and medium businesses to build, deploy and manage graph-enabled applications rapidly.
Introducing the Neo4j Connector for Apache Spark
Neo4j Connector for Apache Spark is an integration tool to move data bi-directionally between the Neo4j Graph Platform and Apache Spark. The new connector provides easy, bi-directional access between Neo4j graph datasets and many other data sources – including relational databases, semistructured and unstructured (NoSQL) repositories – transforming data from tables to graphs and back as needed.
Neo4j BI Connector Brings the Power of Graph Databases to the World’s Most Popular Data Discovery Tools
The Neo4j BI Connector is the first enterprise-ready driver to bring graph data to the Business Intelligence (BI) market. The Neo4j BI Connector presents live graph datasets for analysis within popular BI technologies such as Tableau, Looker, TIBCO Spotfire, Oracle Analytics Cloud, MicroStrategy and more.
Data Science
Introducing Neo4j for Graph Data Science, the First Enterprise Graph Framework for Data Scientists
Neo4j announced the availability of Neo4j for Graph Data Science, the first data science environment built to harness the predictive power of relationships for enterprise deployments. Neo4j for Graph Data Science helps data scientists leverage highly predictive, yet largely underutilized relationships and network structures to answer unwieldy problems.
An updated version of Neo4j for Graph Data Science was also released later in the year. This is the first graph machine learning for the enterprise and a breakthrough that democratizes advanced graph-based machine learning (ML) techniques by leveraging deep learning and graph convolutional neural networks. Version 1.4 upended the way enterprises make predictions in diverse scenarios from fraud detection to tracking customer or patient journey, to drug discovery and knowledge graph completion.
Applying Graphs to Real-World Problems
NASA, ICIJ, ATPCO, Lyft and More Choose Neo4j for their Knowledge Graphs
The Knowledge Graph Quick Start program was released to support Neo4j’s rapidly growing knowledge graph customer base. This market acceleration is corroborated in the results of an independent survey, “Technology Executive Priorities for Knowledge Graphs” recently conducted by Pulse, which charts a surge in demand for knowledge graphs among large enterprises.
Here are some key results from the survey:
Majority of IT decision makers surveyed (89%) have an active plan to expand their knowledge graph initiatives over the next 12 months
92% of respondents believe that knowledge graphs improve machine learning accuracy and associated processes
An overwhelming majority of technology executives (97%) believe that there’s more potential within their organization for knowledge graph usage
The top three reasons to expand knowledge graphs are to improve machine learning and artificial intelligence systems (60%), open new revenue streams (50%) and connect data silos to make information more accessible (50%)
The World’s Leading Companies Use Neo4j to Manage Supply Chains, Boost Resilience and Ensure Business Continuity
Well, that’s a wrap for 2020 (and if you’re like me, you’re probably glad it’s over). Stay tuned to the Neo4j Newsroom for all the latest updates in 2021. Wishing everyone a healthy and happy new year!
PostgreSQL is the database management system that gained more popularity in our DB-Engines Ranking within the last year than any of the other 360 monitored systems.
We thus declare PostgreSQL as the DBMS of the Year 2020.
For determining the DBMS of the year, we subtracted the popularity scores of January 2020 from the latest scores of January 2021. We use the difference of these numbers, rather than a percentage, because that would favor systems with a tiny popularity at the beginning of the year. The result is a list of DBMSs sorted by how much they managed to increase their popularity in 2020, or in other words, how many additional people started to communicate about it in one of the ways we measure in our methodology, for example job offers, professional profile entries and citations on the web.
DBMS of the Year: PostgreSQL
PostgreSQL already won our DBMS of the Year award in 2017 and 2018, and now becomes the first system to win this title three times.
PostgreSQL is known and loved for its stability and feature set. Recent releases have concentrated primarily on improvements under the hood, increasing its performance and efficiency. For DevOps these enhancements are more than welcome, and our popularity scores show this: PostgreSQL had a popularity score of 167 seven years ago, and they stand now at 552. The gap to our top three systems gets smaller every year.
It is worth mentioning that PostgreSQL is the base technology of various systems in our ranking. We list such systems as separate entries if they provide significant DBMS functionality on top of their base. These systems include Greenplum, EDB Postgres, TimescaleDB, Citus and several more.
Runner-up: Microsoft Azure SQL Database
Microsoft Azure SQL Database is a fully managed database as a service. It is built on the latest stable version of the Microsoft SQL Server product and optimized with features for running in the cloud (auto-scale, geo-replication, automatic tuning, …). Consequently, features like manual backup/restore, management of server configuration parameters are not supported.
Between January 2020 and January 2021 Azure SQL database increased its popularity score from 28.2 points to 71.4 points (impressive 253%) and improved its overall rank in the DB-Engines ranking from 25 to 15.
In the 9 years of DB-Engines, it is the first time that a cloud database service comes in within the top three of the Database of the Year award.
Third place: MongoDB
Mongo is a two-time DBMS of the year winner in 2013 and 2014, and its popularity growth has not stopped since then. It is the most popular NoSQL system, best known as a Document Store. A less-known fact is, that MongoDB is also the most popular Search Engine, when we include secondary database models. That illustrates quite well the ever-expanding scope of MongoDB since its initial release only 11 years ago. Equally important, there is no question that MongoDB is a mature, production-ready system today, and the web-scale jokes from 10 years ago didn’t age particularly well, although, they may have been funny at the time.
We congratulate PostgreSQL, Microsoft and MongoDB on their success in 2020.
Previous winners of the DB-Engines DBMS of the Year Award:
Reactions
Selected statements on the results:
Jonathan Katz, PostgreSQL Core Team Member: “PostgreSQL owes its success to the collaborative, global community of open source developers who are solving the modern challenges of data management. We thank DB-Engines for their continued recognition of PostgreSQL, and we will continue to enhance our developer friendly, open source database system known for its reliability and robustness.”
John ‘JG’ Chirapurath, Vice President, Azure Data, AI & Edge: “We’re thankful for this recognition from DB-Engines and are particularly excited that Azure SQL Database is the first cloud database service to be part of the top three for the DBMS of the Year award. Azure SQL Database is a fully-managed and intelligent service that’s always up to date and built for the cloud. Developers and DBAs choose Azure SQL Database to modernize their existing SQL applications and build new apps in the cloud using familiar SQL Server tools and experiences. We’re looking forward to continued investment in Azure SQL as the preferred destination for SQL Server workloads in the cloud.”
Rishi Dave, CMO, MongoDB: “MongoDB has had a banner year. Our popularity with developers continues to grow, as evidenced by the fact that our community server has been downloaded over 130M times – 55M this year alone – which is more downloads than we had in the first ten years of the company. Our global cloud database, MongoDB Atlas now represents almost 50% of our revenue and it just became the first cloud database to enable an application to run simultaneously across multiple cloud providers with the release of Multi-Cloud Clusters. It is exciting to add this additional recognition from DB-Engines to our list of accomplishments.”


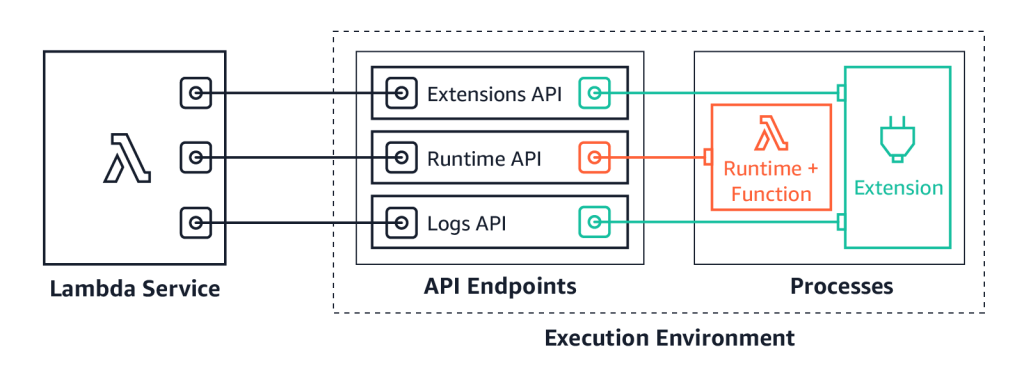
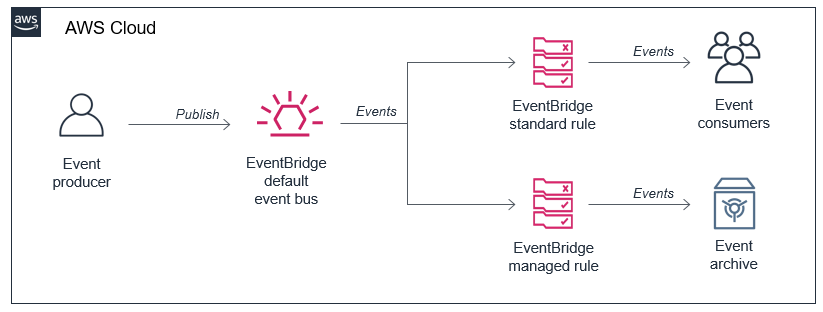
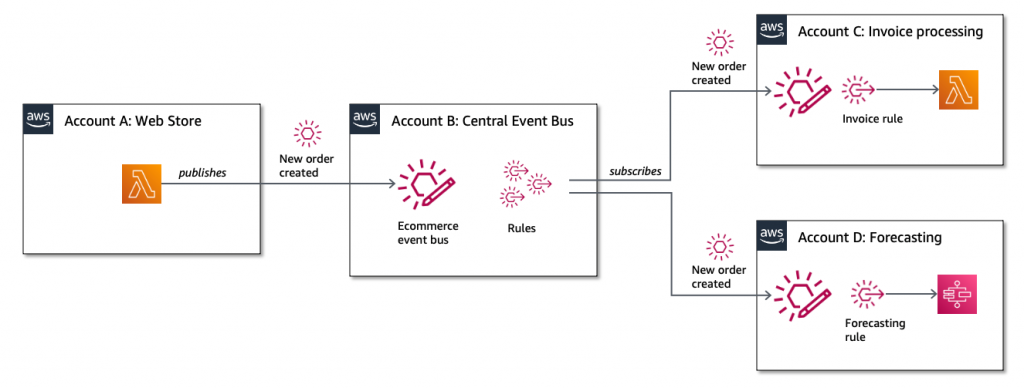
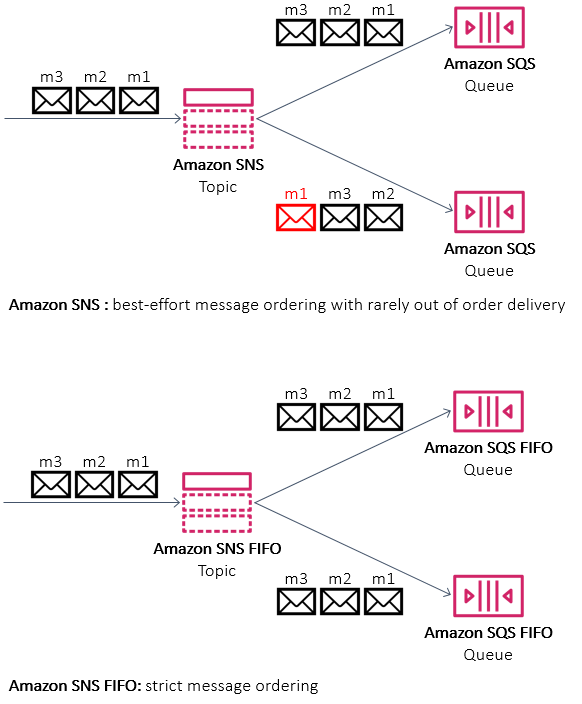












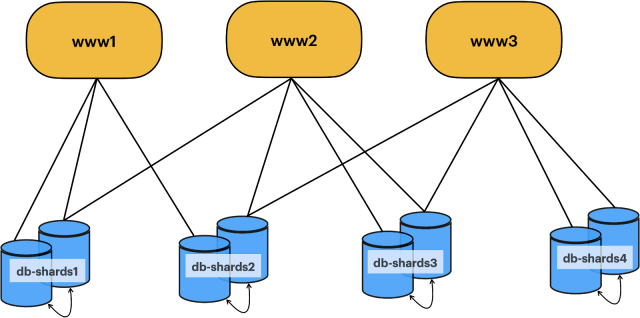
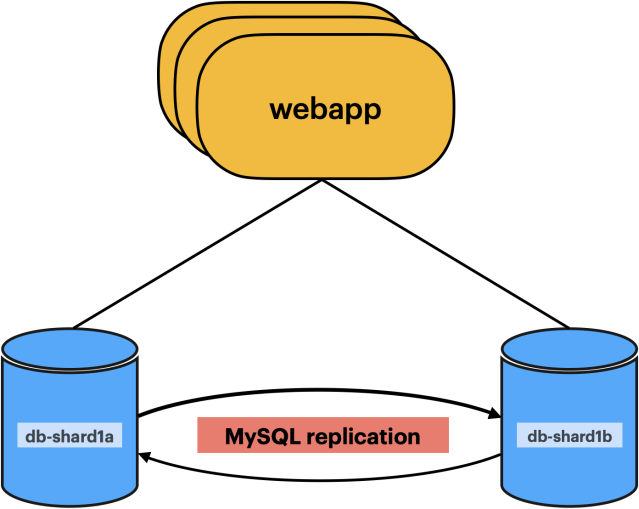

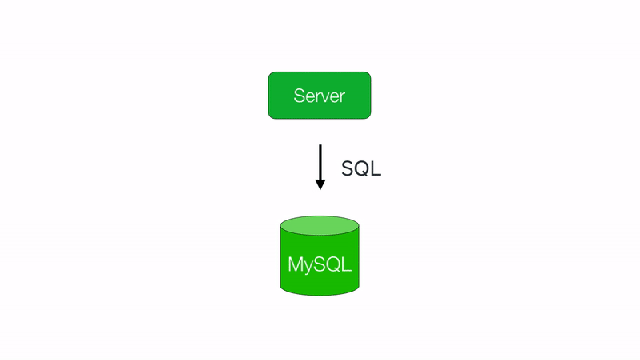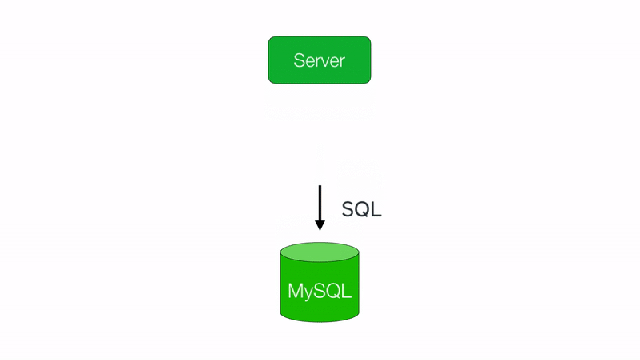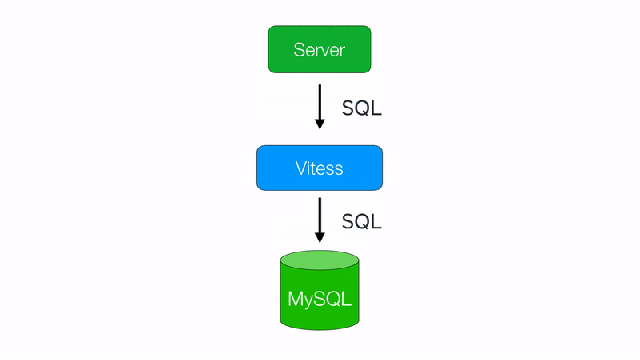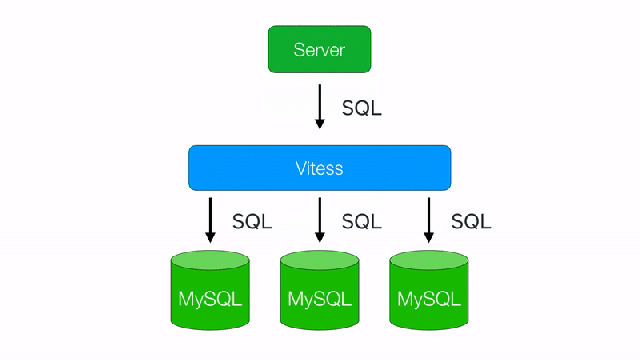
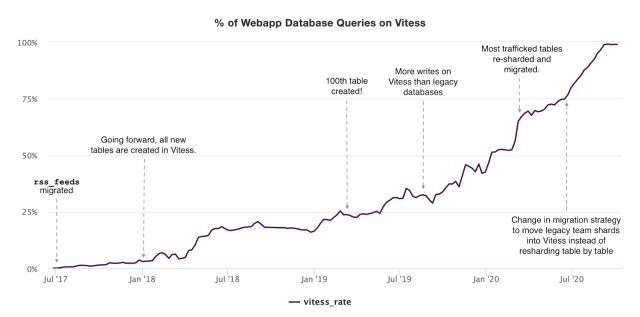
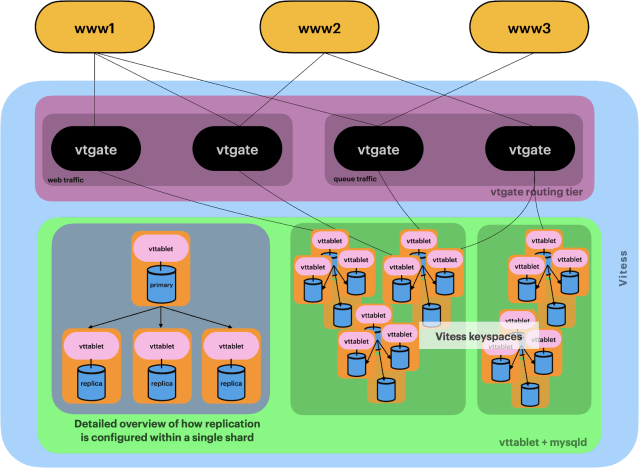





 Herain Oberoi leads Product Marketing for AWS’s Databases, Analytics, BI, and Blockchain services. His team is responsible for helping customers learn about, adopt, and successfully use AWS services. Prior to AWS, he held various product management and marketing leadership roles at Microsoft and a successful startup that was later acquired by BEA Systems. When he’s not working, he enjoys spending time with his family, gardening, and exercising.
Herain Oberoi leads Product Marketing for AWS’s Databases, Analytics, BI, and Blockchain services. His team is responsible for helping customers learn about, adopt, and successfully use AWS services. Prior to AWS, he held various product management and marketing leadership roles at Microsoft and a successful startup that was later acquired by BEA Systems. When he’s not working, he enjoys spending time with his family, gardening, and exercising.





 for Graph Data Platforms, Q4 2020
for Graph Data Platforms, Q4 2020







